Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTT5: Pretraining and validating the T5 model on Brazilian Portuguese data
Paper and Code

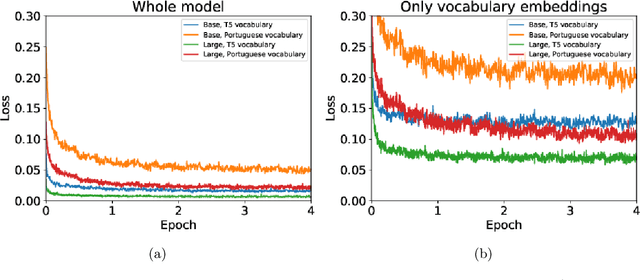


In natural language processing (NLP), there is a need for more resources in Portuguese, since much of the data used in the state-of-the-art research is in other languages. In this paper, we pretrain a T5 model on the BrWac corpus, an extensive collection of web pages in Portuguese, and evaluate its performance against other Portuguese pretrained models and multilingual models on the sentence similarity and sentence entailment tasks. We show that our Portuguese pretrained models have significantly better performance over the original T5 models. Moreover, we showcase the positive impact of using a Portuguese vocabulary.
View paper on