 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTSEFormer: Progressive Temporal-Spatial Enhanced TransFormer Towards Video Object Detection
Paper and Code
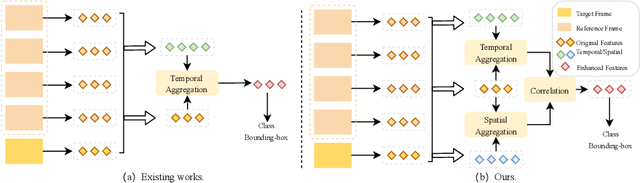
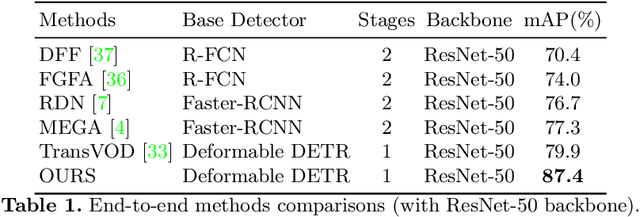


Recent years have witnessed a trend of applying context frames to boost the performance of object detection as video object detection. Existing methods usually aggregate features at one stroke to enhance the feature. These methods, however, usually lack spatial information from neighboring frames and suffer from insufficient feature aggregation. To address the issues, we perform a progressive way to introduce both temporal information and spatial information for an integrated enhancement. The temporal information is introduced by the temporal feature aggregation model (TFAM), by conducting an attention mechanism between the context frames and the target frame (i.e., the frame to be detected). Meanwhile, we employ a Spatial Transition Awareness Model (STAM) to convey the location transition information between each context frame and target frame. Built upon a transformer-based detector DETR, our PTSEFormer also follows an end-to-end fashion to avoid heavy post-processing procedures while achieving 88.1% mAP on the ImageNet VID dataset. Codes are available at https://github.com/Hon-Wong/PTSEFormer.