 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Convolutional Policy Gradient for Sequence-to-Sequence Lip-Reading
Paper and Code
Mar 09, 2020
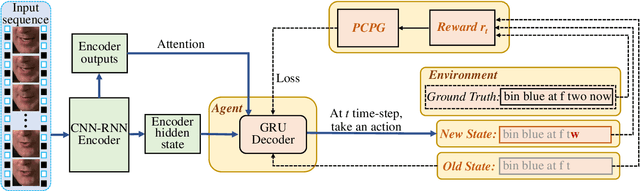
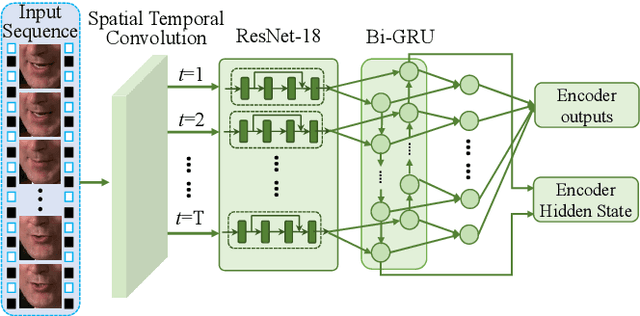
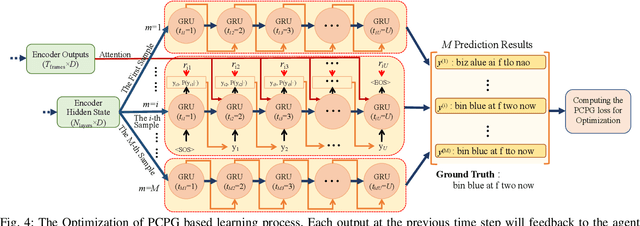
Lip-reading aims to infer the speech content from the lip movement sequence and can be seen as a typical sequence-to-sequence (seq2seq) problem which translates the input image sequence of lip movements to the text sequence of the speech content. However, the traditional learning process of seq2seq models always suffers from two problems: the exposure bias resulted from the strategy of "teacher-forcing", and the inconsistency between the discriminative optimization target (usually the cross-entropy loss) and the final evaluation metric (usually the character/word error rate). In this paper, we propose a novel pseudo-convolutional policy gradient (PCPG) based method to address these two problems. On the one hand, we introduce the evaluation metric (refers to the character error rate in this paper) as a form of reward to optimize the model together with the original discriminative target. On the other hand, inspired by the local perception property of convolutional operation, we perform a pseudo-convolutional operation on the reward and loss dimension, so as to take more context around each time step into account to generate a robust reward and loss for the whole optimization. Finally, we perform a thorough comparison and evaluation on both the word-level and sentence-level benchmarks. The results show a significant improvement over other related methods, and report either a new state-of-the-art performance or a competitive accuracy on all these challenging benchmarks, which clearly proves the advantages of our approach.