 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxy Prompt: Endowing SAM and SAM 2 with Auto-Interactive-Prompt for Medical Segmentation
Paper and Code
Feb 05, 2025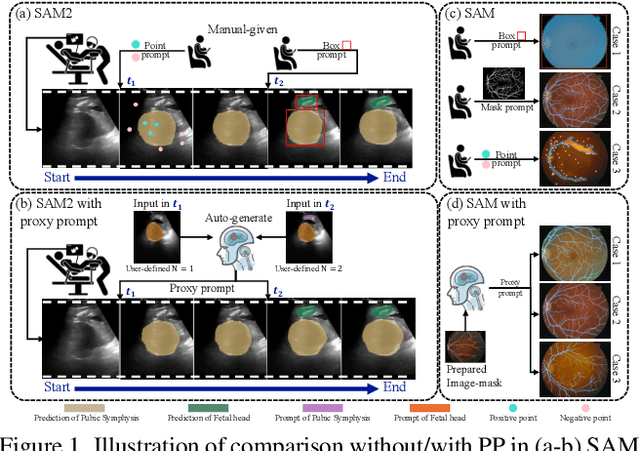
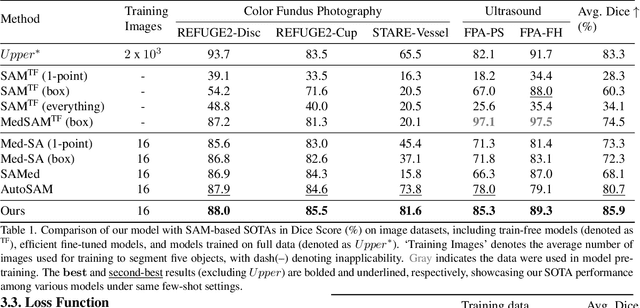
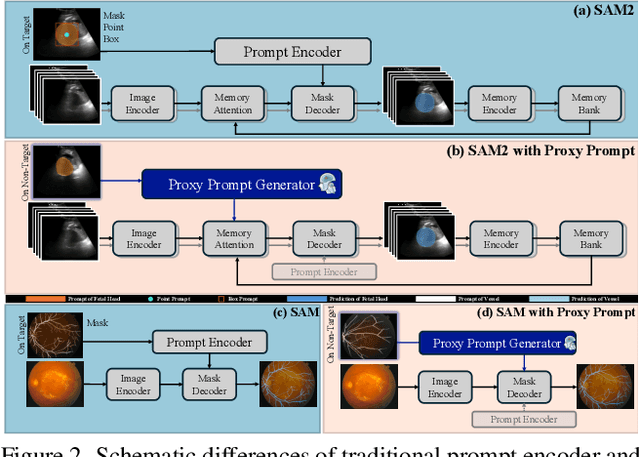

In this paper, we aim to address the unmet demand for automated prompting and enhanced human-model interactions of SAM and SAM2 for the sake of promoting their widespread clinical adoption. Specifically, we propose Proxy Prompt (PP), auto-generated by leveraging non-target data with a pre-annotated mask. We devise a novel 3-step context-selection strategy for adaptively selecting the most representative contextual information from non-target data via vision mamba and selective maps, empowering the guiding capability of non-target image-mask pairs for segmentation on target image/video data. To reinforce human-model interactions in PP, we further propose a contextual colorization module via a dual-reverse cross-attention to enhance interactions between target features and contextual-embedding with amplifying distinctive features of user-defined object(s). Via extensive evaluations, our method achieves state-of-the-art performance on four public datasets and yields comparable results with fully-trained models, even when trained with only 16 image masks.