 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Quasi-Newton for Computationally Intensive L1-regularized M-estimators
Paper and Code
Jan 23, 2015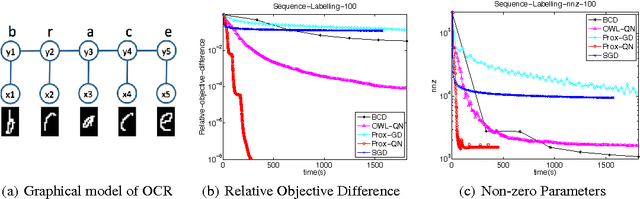
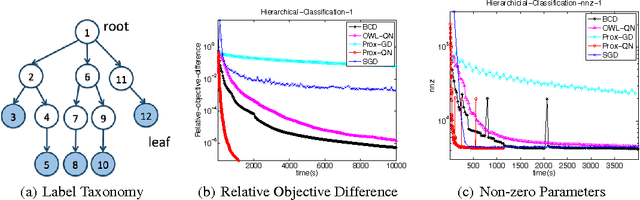
We consider the class of optimization problems arising from computationally intensive L1-regularized M-estimators, where the function or gradient values are very expensive to compute. A particular instance of interest is the L1-regularized MLE for learning Conditional Random Fields (CRFs), which are a popular class of statistical models for varied structured prediction problems such as sequence labeling, alignment, and classification with label taxonomy. L1-regularized MLEs for CRFs are particularly expensive to optimize since computing the gradient values requires an expensive inference step. In this work, we propose the use of a carefully constructed proximal quasi-Newton algorithm for such computationally intensive M-estimation problems, where we employ an aggressive active set selection technique. In a key contribution of the paper, we show that the proximal quasi-Newton method is provably super-linearly convergent, even in the absence of strong convexity, by leveraging a restricted variant of strong convexity. In our experiments, the proposed algorithm converges considerably faster than current state-of-the-art on the problems of sequence labeling and hierarchical classification.