 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Sample Efficient RLHF via Active Preference Optimization
Paper and Code
Feb 16, 2024
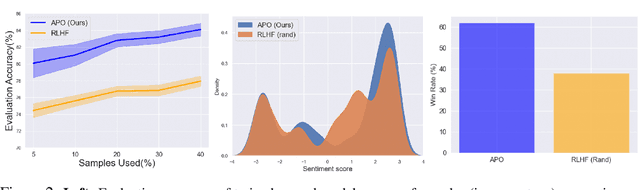


Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. While these aligned generative models have demonstrated impressive capabilities across various tasks, the dependence on high-quality human preference data poses a costly bottleneck in practical implementation of RLHF. Hence better and adaptive strategies for data collection is needed. To this end, we frame RLHF as a contextual preference bandit problem with prompts as contexts and show that the naive way of collecting preference data by choosing prompts uniformly at random leads to a policy that suffers an $\Omega(1)$ suboptimality gap in rewards. Then we propose $\textit{Active Preference Optimization}$ ($\texttt{APO}$), an algorithm that actively selects prompts to collect preference data. Under the Bradley-Terry-Luce (BTL) preference model, \texttt{APO} achieves sample efficiency without compromising on policy performance. We show that given a sample budget of $T$, the suboptimality gap of a policy learned via $\texttt{APO}$ scales as $O(1/\sqrt{T})$. Next, we propose a compute-efficient batch version of $\texttt{APO}$ with minor modification and evaluate its performance in practice. Experimental evaluations on a human preference dataset validate \texttt{APO}'s efficacy as a sample-efficient and practical solution to data collection for RLHF, facilitating alignment of LLMs with human preferences in a cost-effective and scalable manner.