 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic segmentation for parsing spoken dialogue
Paper and Code
May 26, 2021
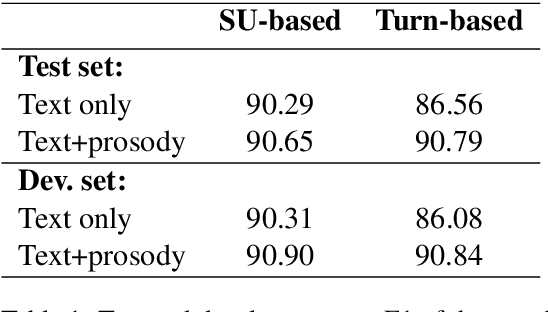


Parsing spoken dialogue poses unique difficulties, including disfluencies and unmarked boundaries between sentence-like units. Previous work has shown that prosody can help with parsing disfluent speech (Tran et al. 2018), but has assumed that the input to the parser is already segmented into sentence-like units (SUs), which isn't true in existing speech applications. We investigate how prosody affects a parser that receives an entire dialogue turn as input (a turn-based model), instead of gold standard pre-segmented SUs (an SU-based model). In experiments on the English Switchboard corpus, we find that when using transcripts alone, the turn-based model has trouble segmenting SUs, leading to worse parse performance than the SU-based model. However, prosody can effectively replace gold standard SU boundaries: with prosody, the turn-based model performs as well as the SU-based model (90.79 vs. 90.65 F1 score, respectively), despite performing two tasks (SU segmentation and parsing) rather than one (parsing alone). Analysis shows that pitch and intensity features are the most important for this corpus, since they allow the model to correctly distinguish an SU boundary from a speech disfluency -- a distinction that the model otherwise struggles to make.