 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSelfLC: Progressive Self Label Correction Towards A Low-Temperature Entropy State
Paper and Code
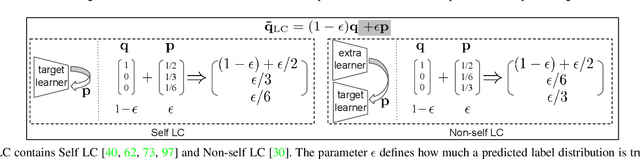

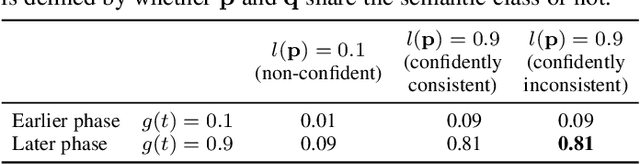
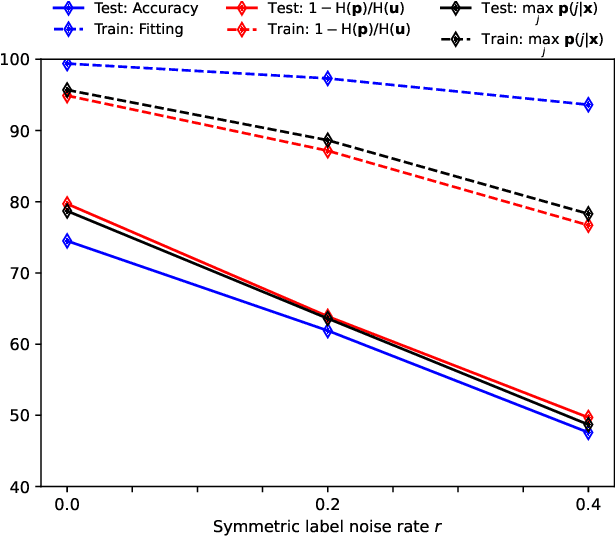
To train robust deep neural networks (DNNs), we systematically study several target modification approaches, which include output regularisation, self and non-self label correction (LC). Three key issues are discovered: (1) Self LC is the most appealing as it exploits its own knowledge and requires no extra models. However, how to automatically decide the trust degree of a learner as training goes is not well answered in the literature. (2) Some methods penalise while the others reward low-entropy predictions, prompting us to ask which one is better. (3) Using the standard training setting, a trained network is of low confidence when severe noise exists, making it hard to leverage its high-entropy self knowledge. To resolve the issue (1), taking two well-accepted propositions--deep neural networks learn meaningful patterns before fitting noise and minimum entropy regularisation principle--we propose a novel end-to-end method named ProSelfLC, which is designed according to learning time and entropy. Specifically, given a data point, we progressively increase trust in its predicted label distribution versus its annotated one if a model has been trained for enough time and the prediction is of low entropy (high confidence). For the issue (2), according to ProSelfLC, we empirically prove that it is better to redefine a meaningful low-entropy status and optimise the learner toward it. This serves as a defence of entropy minimisation. To address the issue (3), we decrease the entropy of self knowledge using a low temperature before exploiting it to correct labels, so that the revised labels redefine a low-entropy target state. We demonstrate the effectiveness of ProSelfLC through extensive experiments in both clean and noisy settings, and on both image and protein datasets. Furthermore, our source code is available at https://github.com/XinshaoAmosWang/ProSelfLC-AT.