 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof of Concept: Automatic Type Recognition
Paper and Code

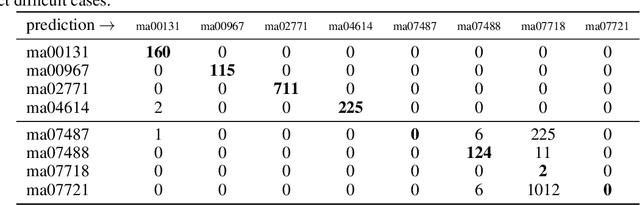
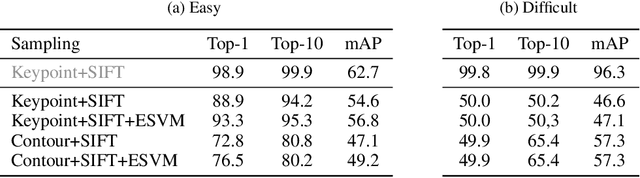
The type used to print an early modern book can give scholars valuable information about the time and place of its production as well as the printer responsible. Currently type recognition is done manually using the shapes of `M' or `Qu' and the size of a type to look it up in a large reference work. This is reliable, but slow and requires specialized skills. We investigate the performance of type classification and type retrieval using a newly created dataset consisting of easy and difficult types used in early printed books. For type classification, we rely on a deep Convolutional Neural Network (CNN) originally used for font-group classification while we use a common writer identification method for the retrieval case. We show that in both scenarios, easy types can be classified/retrieved with a high accuracy while difficult cases are indeed difficult.