 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Enhanced Self-supervised Representation Learning for Remote Sensing Image Understanding
Paper and Code
Sep 28, 2023
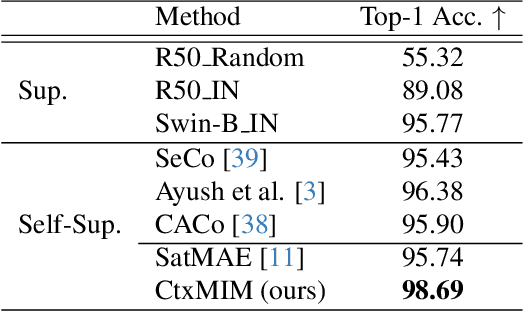

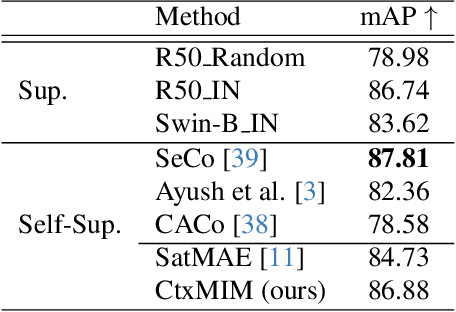
Learning representations through self-supervision on a large-scale, unlabeled dataset has proven to be highly effective for understanding diverse images, such as those used in remote sensing image analysis. However, remote sensing images often have complex and densely populated scenes, with multiple land objects and no clear foreground objects. This intrinsic property can lead to false positive pairs in contrastive learning, or missing contextual information in reconstructive learning, which can limit the effectiveness of existing self-supervised learning methods. To address these problems, we propose a prompt-enhanced self-supervised representation learning method that uses a simple yet efficient pre-training pipeline. Our approach involves utilizing original image patches as a reconstructive prompt template, and designing a prompt-enhanced generative branch that provides contextual information through semantic consistency constraints. We collected a dataset of over 1.28 million remote sensing images that is comparable to the popular ImageNet dataset, but without specific temporal or geographical constraints. Our experiments show that our method outperforms fully supervised learning models and state-of-the-art self-supervised learning methods on various downstream tasks, including land cover classification, semantic segmentation, object detection, and instance segmentation. These results demonstrate that our approach learns impressive remote sensing representations with high generalization and transferability.