 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based Learning for Unpaired Image Captioning
Paper and Code

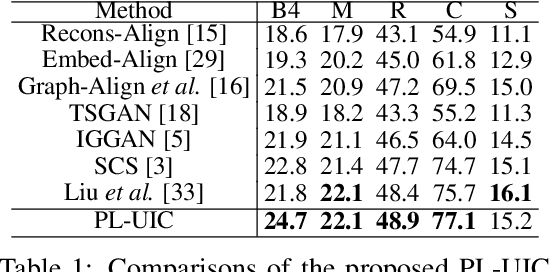
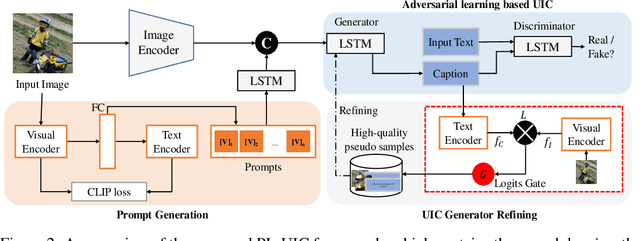
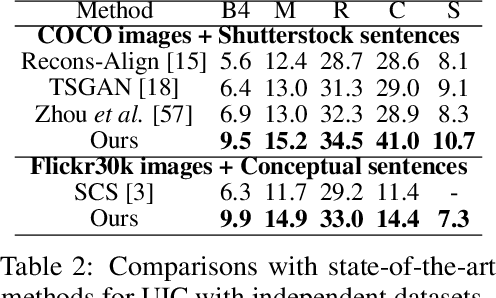
Unpaired Image Captioning (UIC) has been developed to learn image descriptions from unaligned vision-language sample pairs. Existing schemes usually adopt the visual concept reward of reinforcement learning to obtain the alignment between visual concepts and images. However, the cross-domain alignment is usually weak that severely constrains the overall performance of these existing schemes. Recent successes of Vision-Language Pre-Trained Models (VL-PTMs) have triggered the development of prompt-based learning from VL-PTMs. We present in this paper a novel scheme based on prompt to train the UIC model, making best use of the powerful generalization ability and abundant vision-language prior knowledge learned under VL-PTMs. We adopt the CLIP model for this research in unpaired image captioning. Specifically, the visual images are taken as input to the prompt generation module, which contains the pre-trained model as well as one feed-forward layer for prompt extraction. Then, the input images and generated prompts are aggregated for unpaired adversarial captioning learning. To further enhance the potential performance of the captioning, we designed a high-quality pseudo caption filter guided by the CLIP logits to measure correlations between predicted captions and the corresponding images. This allows us to improve the captioning model in a supervised learning manner. Extensive experiments on the COCO and Flickr30K datasets have been carried out to validate the superiority of the proposed model. We have achieved the state-of-the-art performance on the COCO dataset, which outperforms the best UIC model by 1.9% on the BLEU-4 metric. We expect that the proposed prompt-based UIC model will inspire a new line of research for the VL-PTMs based captioning.