 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbNVS: Fast Novel View Synthesis with Learned Probability-Guided Sampling
Paper and Code
Apr 07, 2022

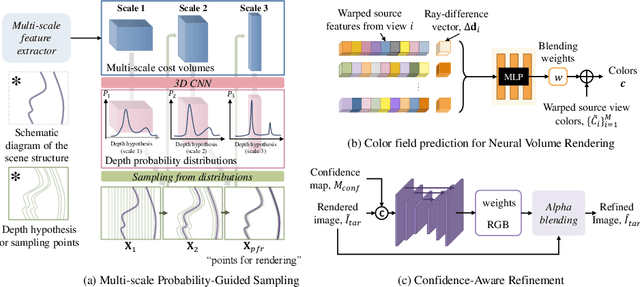
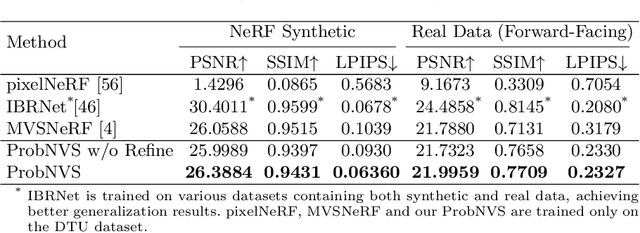
Existing state-of-the-art novel view synthesis methods rely on either fairly accurate 3D geometry estimation or sampling of the entire space for neural volumetric rendering, which limit the overall efficiency. In order to improve the rendering efficiency by reducing sampling points without sacrificing rendering quality, we propose to build a novel view synthesis framework based on learned MVS priors that enables general, fast and photo-realistic view synthesis simultaneously. Specifically, fewer but important points are sampled under the guidance of depth probability distributions extracted from the learned MVS architecture. Based on the learned probability-guided sampling, a neural volume rendering module is elaborately devised to fully aggregate source view information as well as the learned scene structures to synthesize photorealistic target view images. Finally, the rendering results in uncertain, occluded and unreferenced regions can be further improved by incorporating a confidence-aware refinement module. Experiments show that our method achieves 15 to 40 times faster rendering compared to state-of-the-art baselines, with strong generalization capacity and comparable high-quality novel view synthesis performance.