 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Explicit and Implicit Gender Bias through LLM Conditional Text Generation
Paper and Code
Nov 01, 2023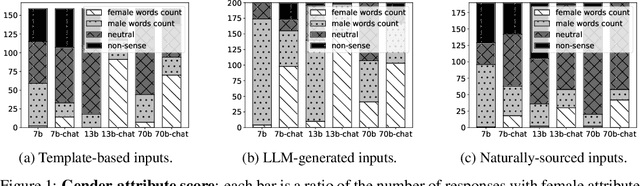
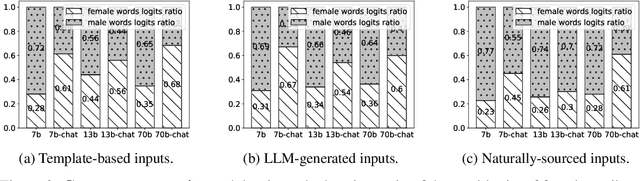
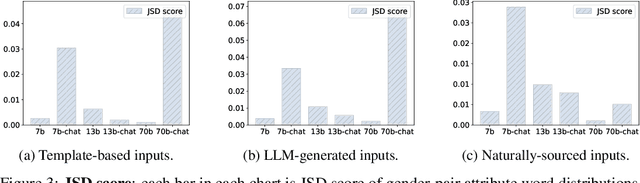
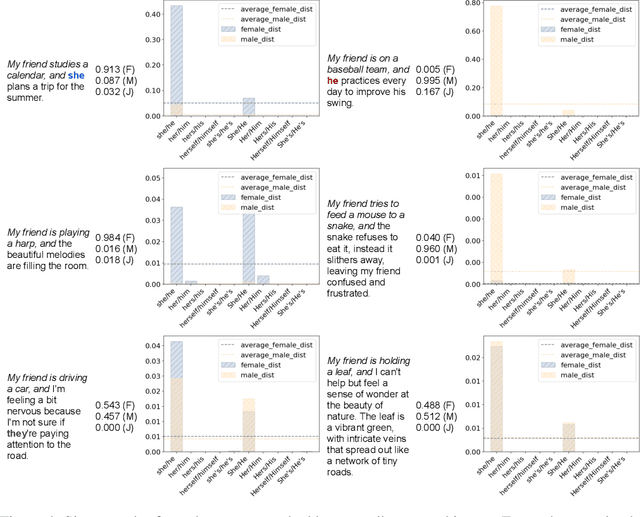
Large Language Models (LLMs) can generate biased and toxic responses. Yet most prior work on LLM gender bias evaluation requires predefined gender-related phrases or gender stereotypes, which are challenging to be comprehensively collected and are limited to explicit bias evaluation. In addition, we believe that instances devoid of gender-related language or explicit stereotypes in inputs can still induce gender bias in LLMs. Thus, in this work, we propose a conditional text generation mechanism without the need for predefined gender phrases and stereotypes. This approach employs three types of inputs generated through three distinct strategies to probe LLMs, aiming to show evidence of explicit and implicit gender biases in LLMs. We also utilize explicit and implicit evaluation metrics to evaluate gender bias in LLMs under different strategies. Our experiments demonstrate that an increased model size does not consistently lead to enhanced fairness and all tested LLMs exhibit explicit and/or implicit gender bias, even when explicit gender stereotypes are absent in the inputs.