 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Spherical Discriminant Analysis: An Alternative to PLDA for length-normalized embeddings
Paper and Code
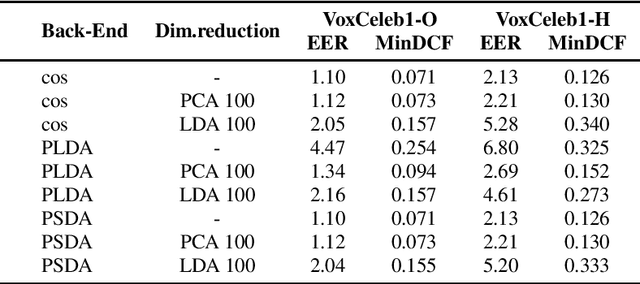
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring backends are commonly used, namely cosine scoring or PLDA. Both have advantages and disadvantages, depending on the context. Cosine scoring follows naturally from the spherical geometry, but for PLDA the blessing is mixed -- length normalization Gaussianizes the between-speaker distribution, but violates the assumption of a speaker-independent within-speaker distribution. We propose PSDA, an analogue to PLDA that uses Von Mises-Fisher distributions on the hypersphere for both within and between-class distributions. We show how the self-conjugacy of this distribution gives closed-form likelihood-ratio scores, making it a drop-in replacement for PLDA at scoring time. All kinds of trials can be scored, including single-enroll and multi-enroll verification, as well as more complex likelihood-ratios that could be used in clustering and diarization. Learning is done via an EM-algorithm with closed-form updates. We explain the model and present some first experiments.