 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Utility Trade-off of Linear Regression under Random Projections and Additive Noise
Paper and Code
Feb 13, 2019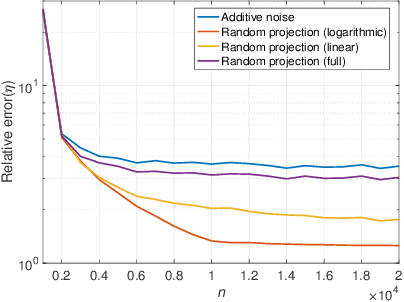


Data privacy is an important concern in machine learning, and is fundamentally at odds with the task of training useful learning models, which typically require the acquisition of large amounts of private user data. One possible way of fulfilling the machine learning task while preserving user privacy is to train the model on a transformed, noisy version of the data, which does not reveal the data itself directly to the training procedure. In this work, we analyze the privacy-utility trade-off of two such schemes for the problem of linear regression: additive noise, and random projections. In contrast to previous work, we consider a recently proposed notion of differential privacy that is based on conditional mutual information (MI-DP), which is stronger than the conventional $(\epsilon, \delta)$-differential privacy, and use relative objective error as the utility metric. We find that projecting the data to a lower-dimensional subspace before adding noise attains a better trade-off in general. We also make a connection between privacy problem and (non-coherent) SIMO, which has been extensively studied in wireless communication, and use tools from there for the analysis. We present numerical results demonstrating the performance of the schemes.