 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy attacks for automatic speech recognition acoustic models in a federated learning framework
Paper and Code
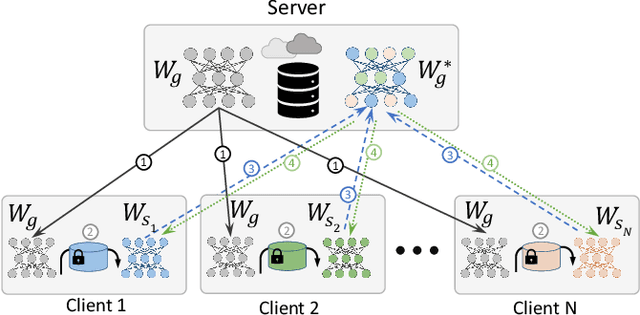



This paper investigates methods to effectively retrieve speaker information from the personalized speaker adapted neural network acoustic models (AMs) in automatic speech recognition (ASR). This problem is especially important in the context of federated learning of ASR acoustic models where a global model is learnt on the server based on the updates received from multiple clients. We propose an approach to analyze information in neural network AMs based on a neural network footprint on the so-called Indicator dataset. Using this method, we develop two attack models that aim to infer speaker identity from the updated personalized models without access to the actual users' speech data. Experiments on the TED-LIUM 3 corpus demonstrate that the proposed approaches are very effective and can provide equal error rate (EER) of 1-2%.