 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorBoost: An Adaptive Algorithm for Learning from Aggregate Responses
Paper and Code
Feb 07, 2024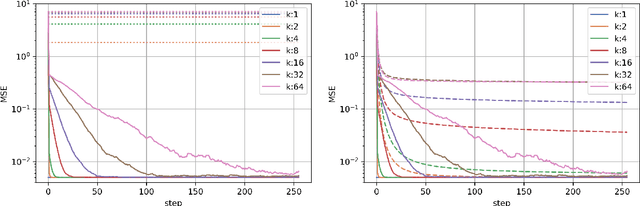
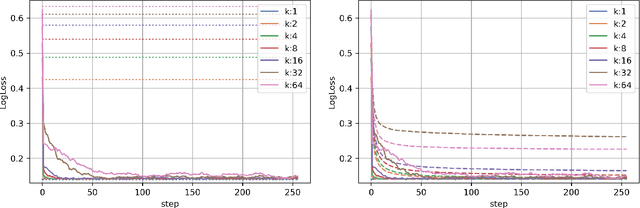
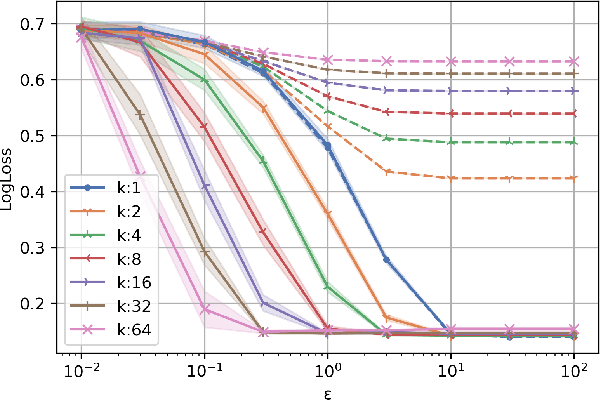
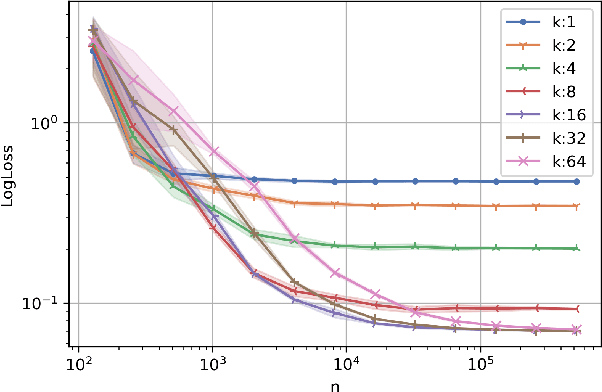
This work studies algorithms for learning from aggregate responses. We focus on the construction of aggregation sets (called bags in the literature) for event-level loss functions. We prove for linear regression and generalized linear models (GLMs) that the optimal bagging problem reduces to one-dimensional size-constrained $k$-means clustering. Further, we theoretically quantify the advantage of using curated bags over random bags. We then propose the PriorBoost algorithm, which adaptively forms bags of samples that are increasingly homogeneous with respect to (unobserved) individual responses to improve model quality. We study label differential privacy for aggregate learning, and we also provide extensive experiments showing that PriorBoost regularly achieves optimal model quality for event-level predictions, in stark contrast to non-adaptive algorithms.