 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREMA: Principled Tensor Data Recovery from Multiple Aggregated Views
Paper and Code
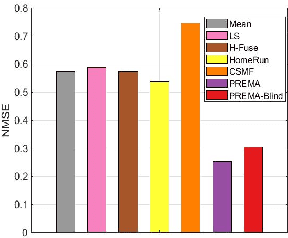

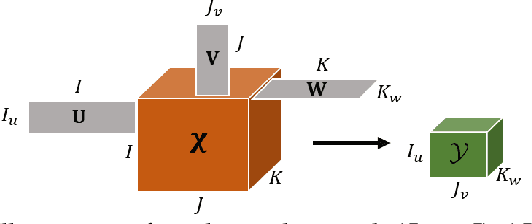
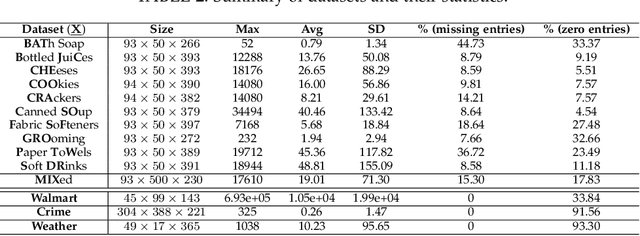
Multidimensional data have become ubiquitous and are frequently involved in situations where the information is aggregated over multiple data atoms. The aggregation can be over time or other features, such as geographical location or group affiliation. We often have access to multiple aggregated views of the same data, each aggregated in one or more dimensions, especially when data are collected or measured by different agencies. However, data mining and machine learning models require detailed data for personalized analysis and prediction. Thus, data disaggregation algorithms are becoming increasingly important in various domains. The goal of this paper is to reconstruct finer-scale data from multiple coarse views, aggregated over different (subsets of) dimensions. The proposed method, called PREMA, leverages low-rank tensor factorization tools to provide recovery guarantees under certain conditions. PREMA is flexible in the sense that it can perform disaggregation on data that have missing entries, i.e., partially observed. The proposed method considers challenging scenarios: i) the available views of the data are aggregated in two dimensions, i.e., double aggregation, and ii) the aggregation patterns are unknown. Experiments on real data from different domains, i.e., sales data from retail companies, crime counts, and weather observations, are presented to showcase the effectiveness of PREMA.