 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Completion: Large-scale Collaborative Ranking from Pairwise Comparisons
Paper and Code
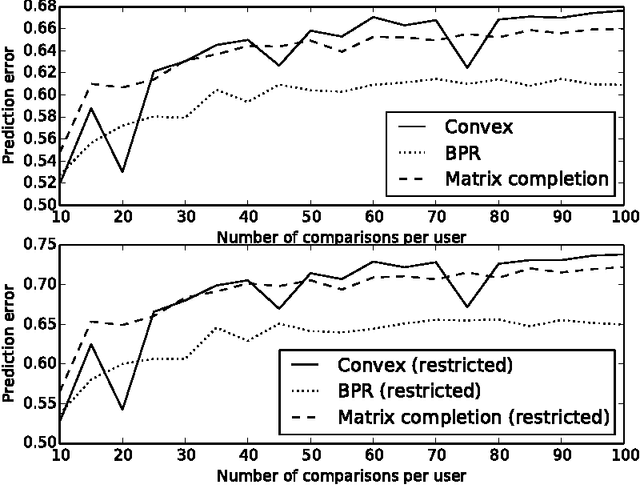

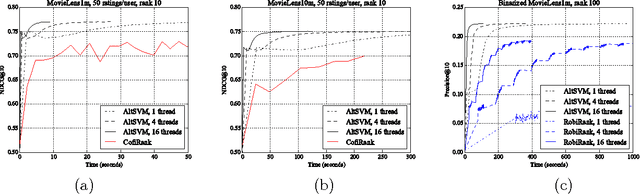
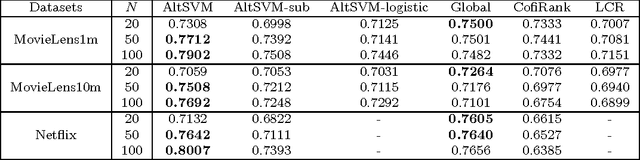
In this paper we consider the collaborative ranking setting: a pool of users each provides a small number of pairwise preferences between $d$ possible items; from these we need to predict preferences of the users for items they have not yet seen. We do so by fitting a rank $r$ score matrix to the pairwise data, and provide two main contributions: (a) we show that an algorithm based on convex optimization provides good generalization guarantees once each user provides as few as $O(r\log^2 d)$ pairwise comparisons -- essentially matching the sample complexity required in the related matrix completion setting (which uses actual numerical as opposed to pairwise information), and (b) we develop a large-scale non-convex implementation, which we call AltSVM, that trains a factored form of the matrix via alternating minimization (which we show reduces to alternating SVM problems), and scales and parallelizes very well to large problem settings. It also outperforms common baselines on many moderately large popular collaborative filtering datasets in both NDCG and in other measures of ranking performance.