 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Inference with Weak Supervision
Paper and Code
Feb 09, 2022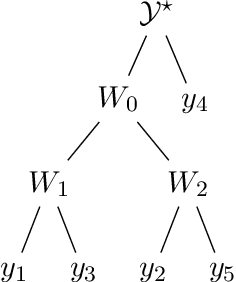
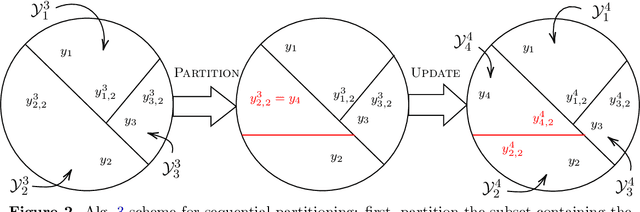
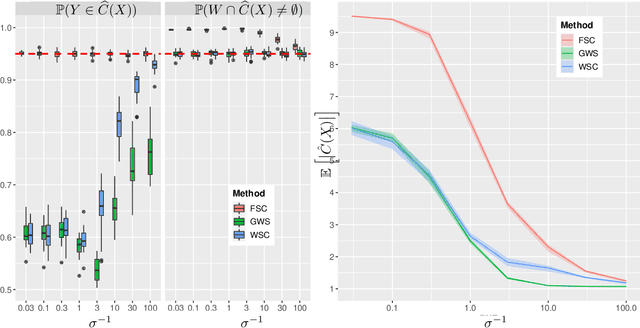
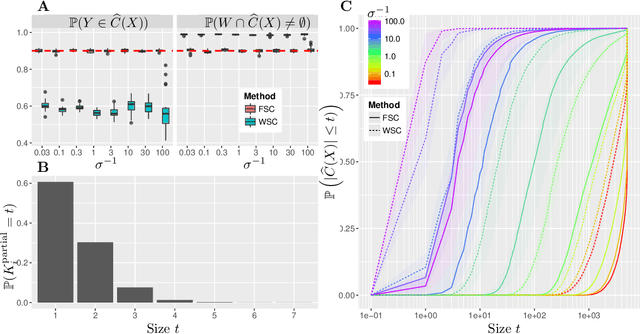
The expense of acquiring labels in large-scale statistical machine learning makes partially and weakly-labeled data attractive, though it is not always apparent how to leverage such data for model fitting or validation. We present a methodology to bridge the gap between partial supervision and validation, developing a conformal prediction framework to provide valid predictive confidence sets -- sets that cover a true label with a prescribed probability, independent of the underlying distribution -- using weakly labeled data. To do so, we introduce a (necessary) new notion of coverage and predictive validity, then develop several application scenarios, providing efficient algorithms for classification and several large-scale structured prediction problems. We corroborate the hypothesis that the new coverage definition allows for tighter and more informative (but valid) confidence sets through several experiments.