 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Accuracy of a Few-Shot Classifier
Paper and Code
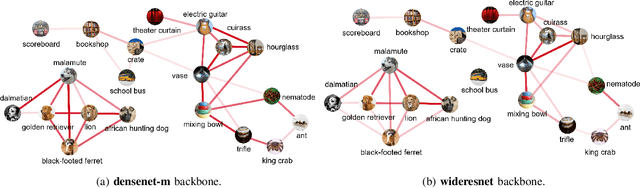
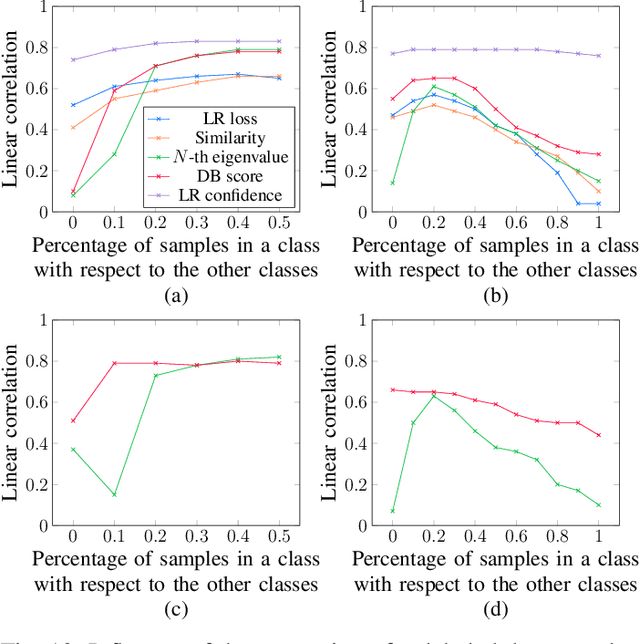
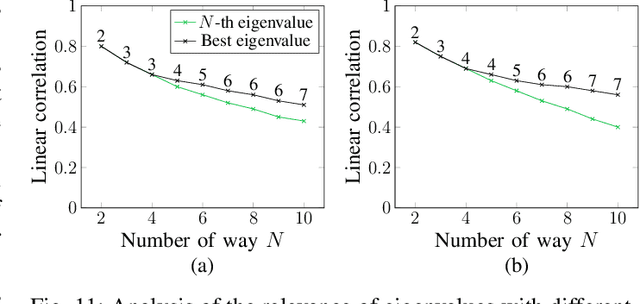
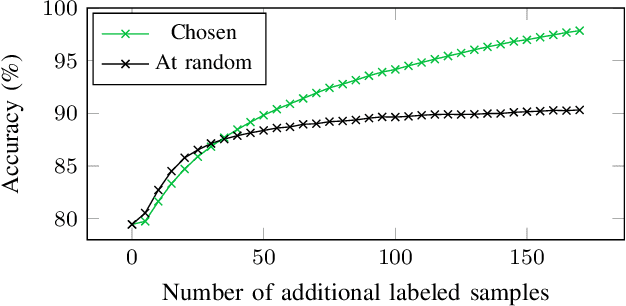
In the context of few-shot learning, one cannot measure the generalization ability of a trained classifier using validation sets, due to the small number of labeled samples. In this paper, we are interested in finding alternatives to answer the question: is my classifier generalizing well to previously unseen data? We first analyze the reasons for the variability of generalization performances. We then investigate the case of using transfer-based solutions, and consider three settings: i) supervised where we only have access to a few labeled samples, ii) semi-supervised where we have access to both a few labeled samples and a set of unlabeled samples and iii) unsupervised where we only have access to unlabeled samples. For each setting, we propose reasonable measures that we empirically demonstrate to be correlated with the generalization ability of considered classifiers. We also show that these simple measures can be used to predict generalization up to a certain confidence. We conduct our experiments on standard few-shot vision datasets.