 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Machine Learning
Paper and Code

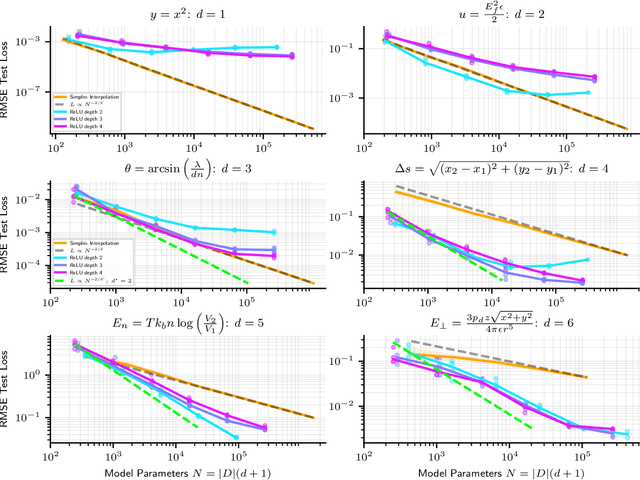


We explore unique considerations involved in fitting ML models to data with very high precision, as is often required for science applications. We empirically compare various function approximation methods and study how they scale with increasing parameters and data. We find that neural networks can often outperform classical approximation methods on high-dimensional examples, by auto-discovering and exploiting modular structures therein. However, neural networks trained with common optimizers are less powerful for low-dimensional cases, which motivates us to study the unique properties of neural network loss landscapes and the corresponding optimization challenges that arise in the high precision regime. To address the optimization issue in low dimensions, we develop training tricks which enable us to train neural networks to extremely low loss, close to the limits allowed by numerical precision.