 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization
Paper and Code



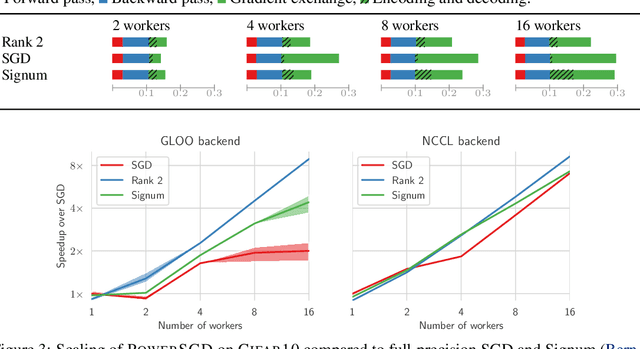
We study gradient compression methods to alleviate the communication bottleneck in data-parallel distributed optimization. Despite the significant attention received, current compression schemes either do not scale well or fail to achieve the target test accuracy. We propose a new low-rank gradient compressor based on power iteration that can i) compress gradients rapidly, ii) efficiently aggregate the compressed gradients using all-reduce, and iii) achieve test performance on par with SGD. The proposed algorithm is the only method evaluated that achieves consistent wall-clock speedups when benchmarked against regular SGD with an optimized communication backend. We demonstrate reduced training times for convolutional networks as well as LSTMs on common datasets. Our code is available at https://github.com/epfml/powersgd.