 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient Algorithms with Monte-Carlo Tree Search for Non-Markov Decision Processes
Paper and Code
Jun 02, 2022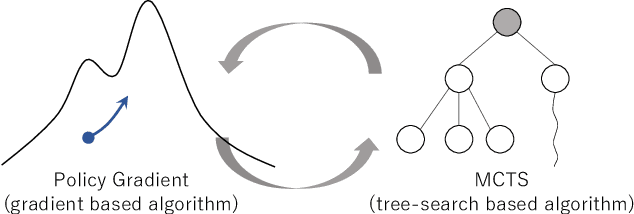
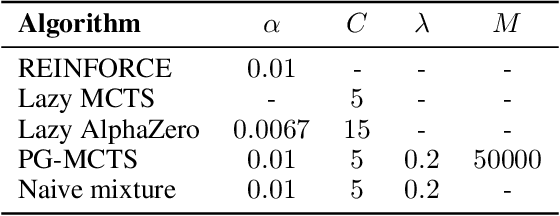
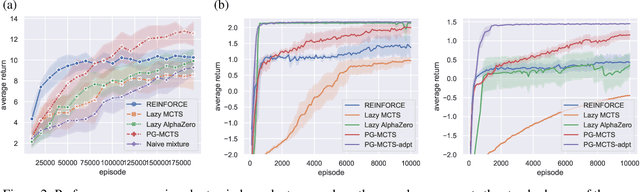

Policy gradient (PG) is a reinforcement learning (RL) approach that optimizes a parameterized policy model for an expected return using gradient ascent. Given a well-parameterized policy model, such as a neural network model, with appropriate initial parameters, the PG algorithms work well even when environment does not have the Markov property. Otherwise, they can be trapped on a plateau or suffer from peakiness effects. As another successful RL approach, algorithms based on Monte-Carlo Tree Search (MCTS), which include AlphaZero, have obtained groundbreaking results especially on the board game playing domain. They are also suitable to be applied to non-Markov decision processes. However, since the standard MCTS does not have the ability to learn state representation, the size of the tree-search space can be too large to search. In this work, we examine a mixture policy of PG and MCTS to complement each other's difficulties and take advantage of them. We derive conditions for asymptotic convergence with results of a two-timescale stochastic approximation and propose an algorithm that satisfies these conditions. The effectivity of the proposed methods is verified through numerical experiments on non-Markov decision processes.