 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-to-Point Video Generation
Paper and Code
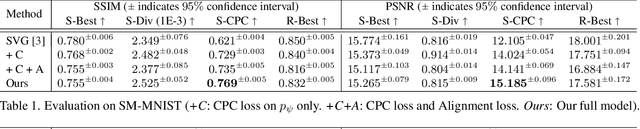
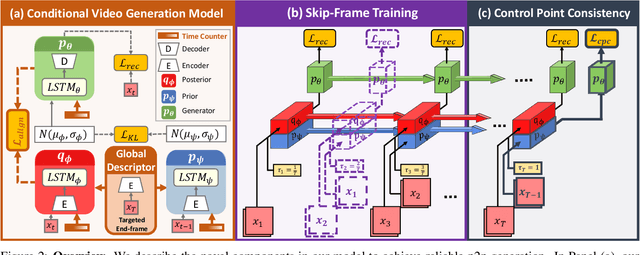
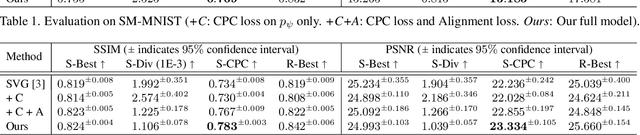
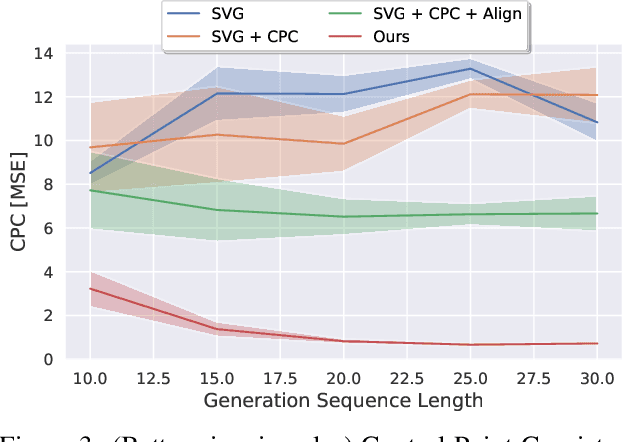
While image manipulation achieves tremendous breakthroughs (e.g., generating realistic faces) in recent years, video generation is much less explored and harder to control, which limits its applications in the real world. For instance, video editing requires temporal coherence across multiple clips and thus poses both start and end constraints within a video sequence. We introduce point-to-point video generation that controls the generation process with two control points: the targeted start- and end-frames. The task is challenging since the model not only generates a smooth transition of frames, but also plans ahead to ensure that the generated end-frame conforms to the targeted end-frame for videos of various length. We propose to maximize the modified variational lower bound of conditional data likelihood under a skip-frame training strategy. Our model can generate sequences such that their end-frame is consistent with the targeted end-frame without loss of quality and diversity. Extensive experiments are conducted on Stochastic Moving MNIST, Weizmann Human Action, and Human3.6M to evaluate the effectiveness of the proposed method. We demonstrate our method under a series of scenarios (e.g., dynamic length generation) and the qualitative results showcase the potential and merits of point-to-point generation. For project page, see https://zswang666.github.io/P2PVG-Project-Page/