 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixle: a fast and effective black-box attack based on rearranging pixels
Paper and Code

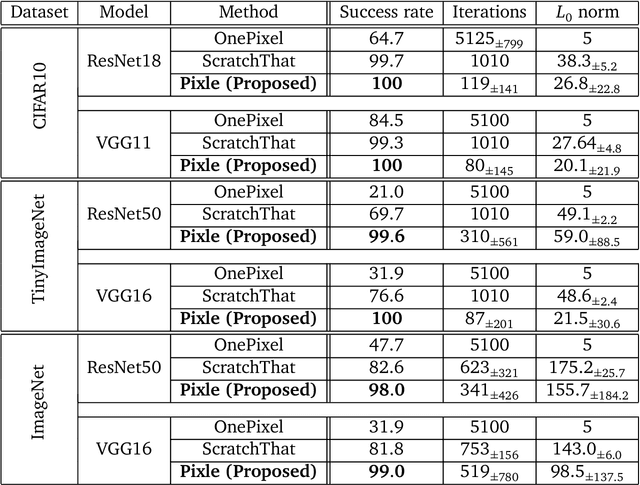
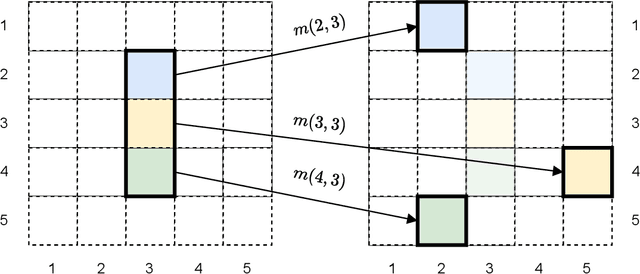
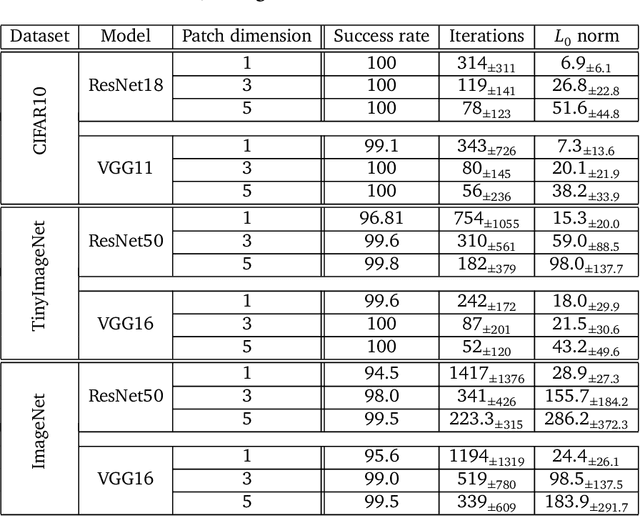
Recent research has found that neural networks are vulnerable to several types of adversarial attacks, where the input samples are modified in such a way that the model produces a wrong prediction that misclassifies the adversarial sample. In this paper we focus on black-box adversarial attacks, that can be performed without knowing the inner structure of the attacked model, nor the training procedure, and we propose a novel attack that is capable of correctly attacking a high percentage of samples by rearranging a small number of pixels within the attacked image. We demonstrate that our attack works on a large number of datasets and models, that it requires a small number of iterations, and that the distance between the original sample and the adversarial one is negligible to the human eye.