 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPAL: a Large-Scale Image Quality Assessment Dataset for Perceptual Image Restoration
Paper and Code
Jul 23, 2020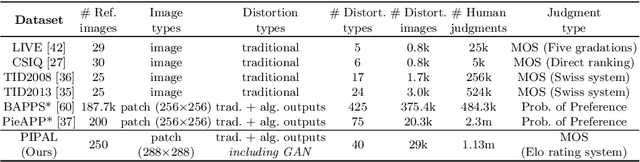


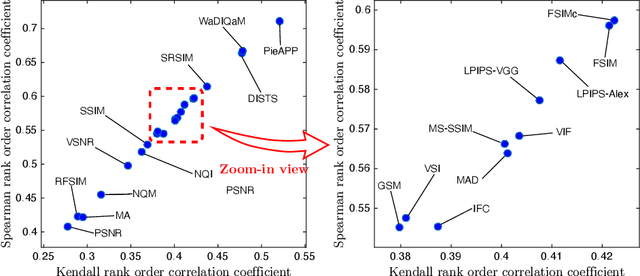
Image quality assessment (IQA) is the key factor for the fast development of image restoration (IR) algorithms. The most recent IR methods based on Generative Adversarial Networks (GANs) have achieved significant improvement in visual performance, but also presented great challenges for quantitative evaluation. Notably, we observe an increasing inconsistency between perceptual quality and the evaluation results. Then we raise two questions: (1) Can existing IQA methods objectively evaluate recent IR algorithms? (2) When focus on beating current benchmarks, are we getting better IR algorithms? To answer these questions and promote the development of IQA methods, we contribute a large-scale IQA dataset, called Perceptual Image Processing Algorithms (PIPAL) dataset. Especially, this dataset includes the results of GAN-based methods, which are missing in previous datasets. We collect more than 1.13 million human judgments to assign subjective scores for PIPAL images using the more reliable "Elo system". Based on PIPAL, we present new benchmarks for both IQA and super-resolution methods. Our results indicate that existing IQA methods cannot fairly evaluate GAN-based IR algorithms. While using appropriate evaluation methods is important, IQA methods should also be updated along with the development of IR algorithms. At last, we improve the performance of IQA networks on GAN-based distortions by introducing anti-aliasing pooling. Experiments show the effectiveness of the proposed method.