 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhenotyping of Clinical Notes with Improved Document Classification Models Using Contextualized Neural Language Models
Paper and Code
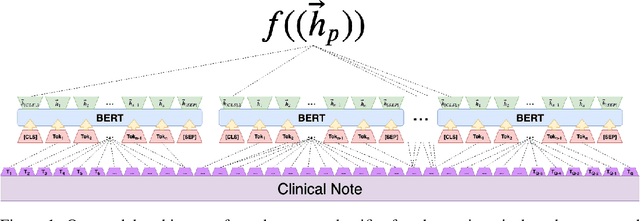
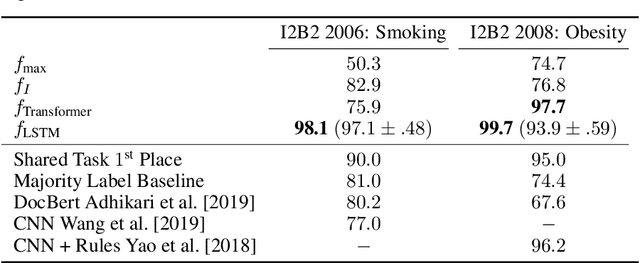
Clinical notes contain an extensive record of a patient's health status, such as smoking status or the presence of heart conditions. However, this detail is not replicated within the structured data of electronic health systems. Phenotyping, the extraction of patient conditions from free clinical text, is a critical task which supports avariety of downstream applications such as decision support and secondary use ofmedical records. Previous work has resulted in systems which are high performing but require hand engineering, often of rules. Recent work in pretrained contextualized language models have enabled advances in representing text for a variety of tasks. We therefore explore several architectures for modeling pheno-typing that rely solely on BERT representations of the clinical note, removing the need for manual engineering. We find these architectures are competitive with or outperform existing state of the art methods on two phenotyping tasks.