 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance optimizations on deep noise suppression models
Paper and Code
Oct 08, 2021
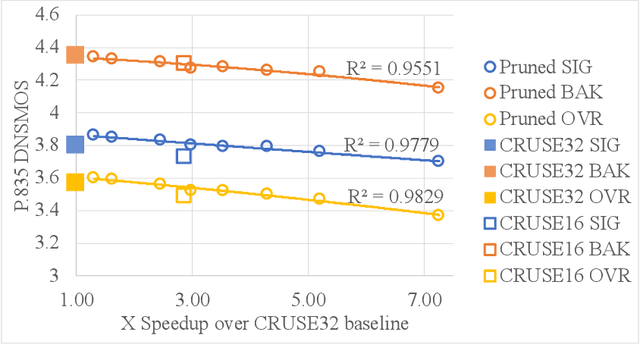
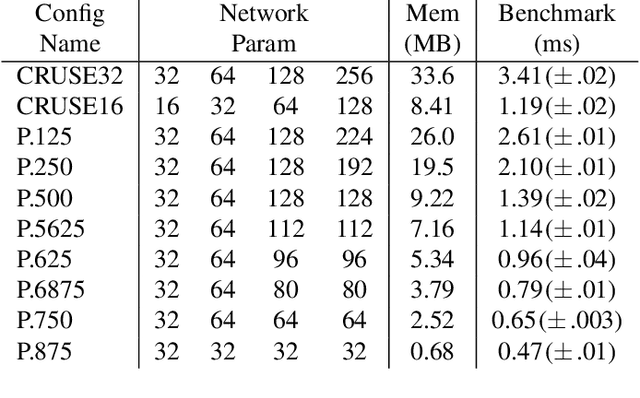
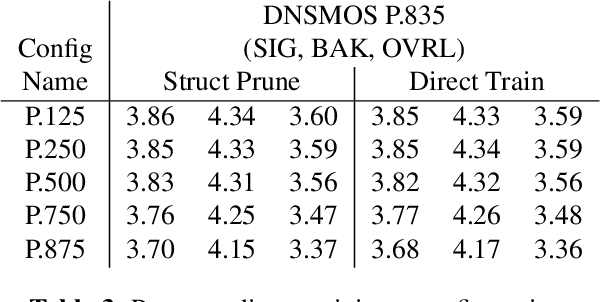
We study the role of magnitude structured pruning as an architecture search to speed up the inference time of a deep noise suppression (DNS) model. While deep learning approaches have been remarkably successful in enhancing audio quality, their increased complexity inhibits their deployment in real-time applications. We achieve up to a 7.25X inference speedup over the baseline, with a smooth model performance degradation. Ablation studies indicate that our proposed network re-parameterization (i.e., size per layer) is the major driver of the speedup, and that magnitude structured pruning does comparably to directly training a model in the smaller size. We report inference speed because a parameter reduction does not necessitate speedup, and we measure model quality using an accurate non-intrusive objective speech quality metric.