 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfectly Accurate Membership Inference by a Dishonest Central Server in Federated Learning
Paper and Code
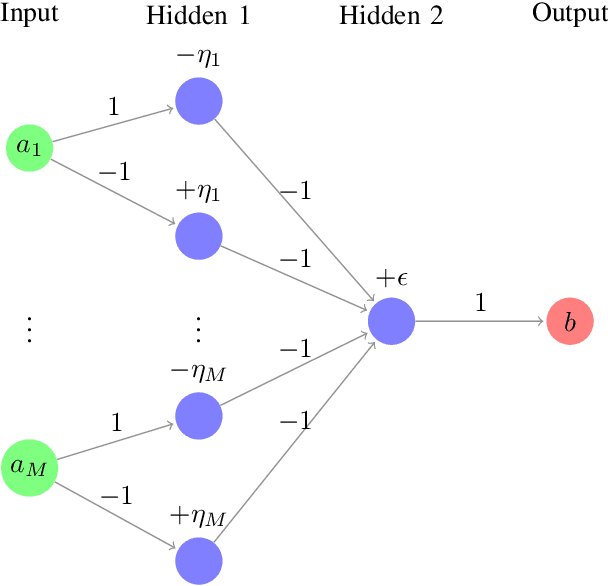

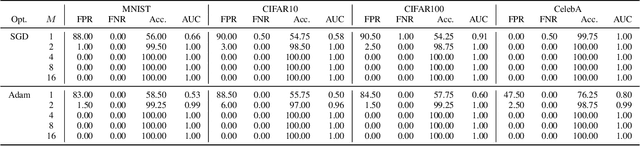

Federated Learning is expected to provide strong privacy guarantees, as only gradients or model parameters but no plain text training data is ever exchanged either between the clients or between the clients and the central server. In this paper, we challenge this claim by introducing a simple but still very effective membership inference attack algorithm, which relies only on a single training step. In contrast to the popular honest-but-curious model, we investigate a framework with a dishonest central server. Our strategy is applicable to models with ReLU activations and uses the properties of this activation function to achieve perfect accuracy. Empirical evaluation on visual classification tasks with MNIST, CIFAR10, CIFAR100 and CelebA datasets show that our method provides perfect accuracy in identifying one sample in a training set with thousands of samples. Occasional failures of our method lead us to discover duplicate images in the CIFAR100 and CelebA datasets.