 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeerDA: Data Augmentation via Modeling Peer Relation for Span Identification Tasks
Paper and Code



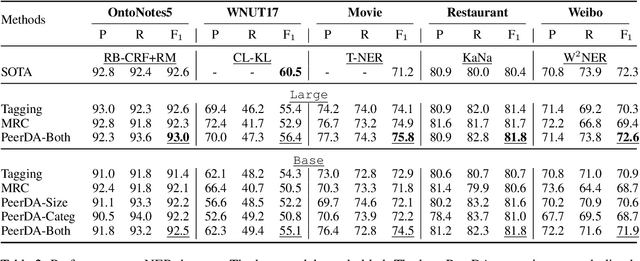
Span Identification (SpanID) is a family of NLP tasks that aims to detect and classify text spans. Different from previous works that merely leverage Subordinate (\textsc{Sub}) relation about \textit{if a span is an instance of a certain category} to train SpanID models, we explore Peer (\textsc{Pr}) relation, which indicates that \textit{the two spans are two different instances from the same category sharing similar features}, and propose a novel \textbf{Peer} \textbf{D}ata \textbf{A}ugmentation (PeerDA) approach to treat span-span pairs with the \textsc{Pr} relation as a kind of augmented training data. PeerDA has two unique advantages: (1) There are a large number of span-span pairs with the \textsc{Pr} relation for augmenting the training data. (2) The augmented data can prevent over-fitting to the superficial span-category mapping by pushing SpanID models to leverage more on spans' semantics. Experimental results on ten datasets over four diverse SpanID tasks across seven domains demonstrate the effectiveness of PeerDA. Notably, seven of them achieve state-of-the-art results.