 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-Aware Self-Supervised Pre-Training for Person Re-Identification
Paper and Code
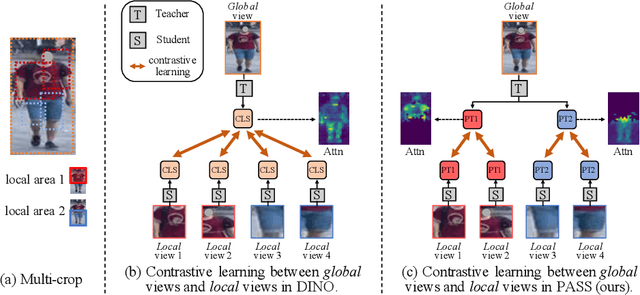
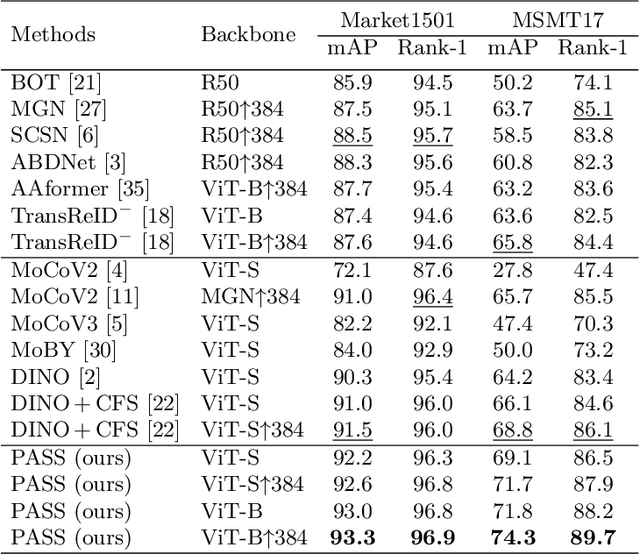
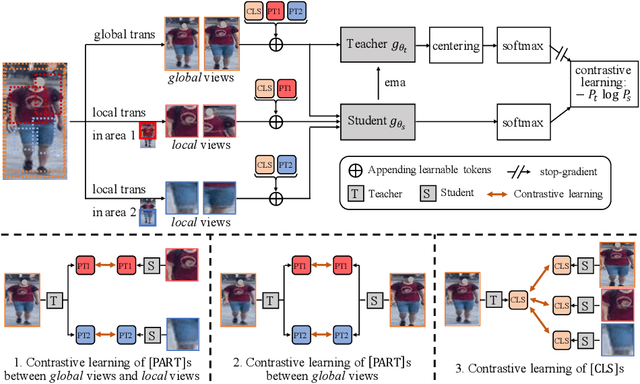
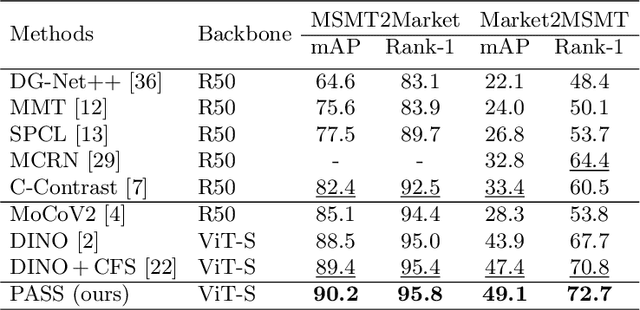
In person re-identification (ReID), very recent researches have validated pre-training the models on unlabelled person images is much better than on ImageNet. However, these researches directly apply the existing self-supervised learning (SSL) methods designed for image classification to ReID without any adaption in the framework. These SSL methods match the outputs of local views (e.g., red T-shirt, blue shorts) to those of the global views at the same time, losing lots of details. In this paper, we propose a ReID-specific pre-training method, Part-Aware Self-Supervised pre-training (PASS), which can generate part-level features to offer fine-grained information and is more suitable for ReID. PASS divides the images into several local areas, and the local views randomly cropped from each area are assigned with a specific learnable [PART] token. On the other hand, the [PART]s of all local areas are also appended to the global views. PASS learns to match the output of the local views and global views on the same [PART]. That is, the learned [PART] of the local views from a local area is only matched with the corresponding [PART] learned from the global views. As a result, each [PART] can focus on a specific local area of the image and extracts fine-grained information of this area. Experiments show PASS sets the new state-of-the-art performances on Market1501 and MSMT17 on various ReID tasks, e.g., vanilla ViT-S/16 pre-trained by PASS achieves 92.2\%/90.2\%/88.5\% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Our codes are available at https://github.com/CASIA-IVA-Lab/PASS-reID.