 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthographic Feature Transform for Monocular 3D Object Detection
Paper and Code
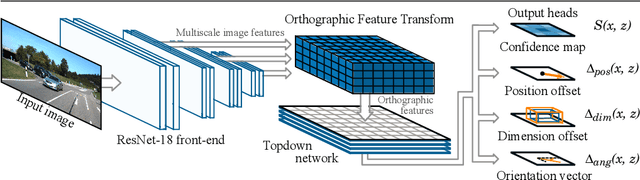
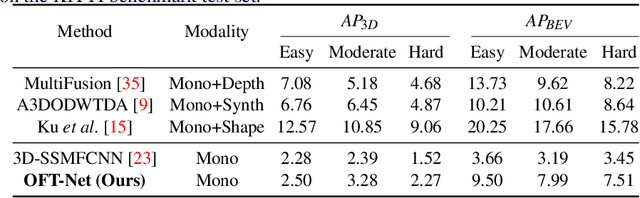
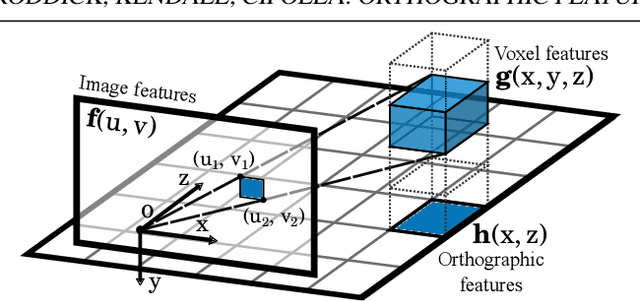
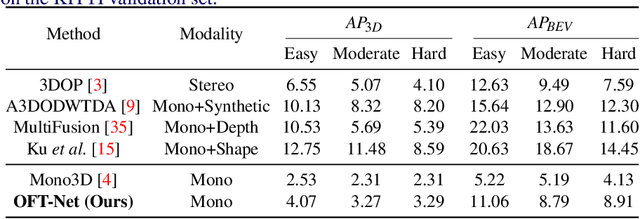
3D object detection from monocular images has proven to be an enormously challenging task, with the performance of leading systems not yet achieving even 10\% of that of LiDAR-based counterparts. One explanation for this performance gap is that existing systems are entirely at the mercy of the perspective image-based representation, in which the appearance and scale of objects varies drastically with depth and meaningful distances are difficult to infer. In this work we argue that the ability to reason about the world in 3D is an essential element of the 3D object detection task. To this end, we introduce the orthographic feature transform, which enables us to escape the image domain by mapping image-based features into an orthographic 3D space. This allows us to reason holistically about the spatial configuration of the scene in a domain where scale is consistent and distances between objects are meaningful. We apply this transformation as part of an end-to-end deep learning architecture and achieve state-of-the-art performance on the KITTI 3D object benchmark.\footnote{We will release full source code and pretrained models upon acceptance of this manuscript for publication.