 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Wasserstein GANs
Paper and Code
Dec 15, 2019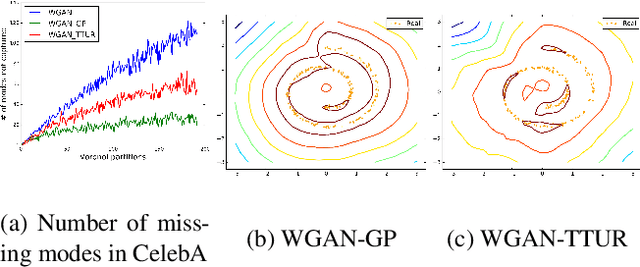
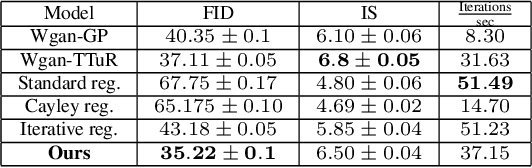
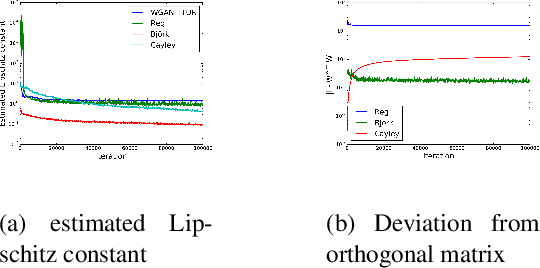

Wasserstein-GANs have been introduced to address the deficiencies of generative adversarial networks (GANs) regarding the problems of vanishing gradients and mode collapse during the training, leading to improved convergence behaviour and improved image quality. However, Wasserstein-GANs require the discriminator to be Lipschitz continuous. In current state-of-the-art Wasserstein-GANs this constraint is enforced via gradient norm regularization. In this paper, we demonstrate that this regularization does not encourage a broad distribution of spectral-values in the discriminator weights, hence resulting in less fidelity in the learned distribution. We therefore investigate the possibility of substituting this Lipschitz constraint with an orthogonality constraint on the weight matrices. We compare three different weight orthogonalization techniques with regards to their convergence properties, their ability to ensure the Lipschitz condition and the achieved quality of the learned distribution. In addition, we provide a comparison to Wasserstein-GANs trained with current state-of-the-art methods, where we demonstrate the potential of solely using orthogonality-based regularization. In this context, we propose an improved training procedure for Wasserstein-GANs which utilizes orthogonalization to further increase its generalization capability. Finally, we provide a novel metric to evaluate the generalization capabilities of the discriminators of different Wasserstein-GANs.