Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Quantiles in Preference-based Markov Decision Processes
Paper and Code
Dec 01, 2016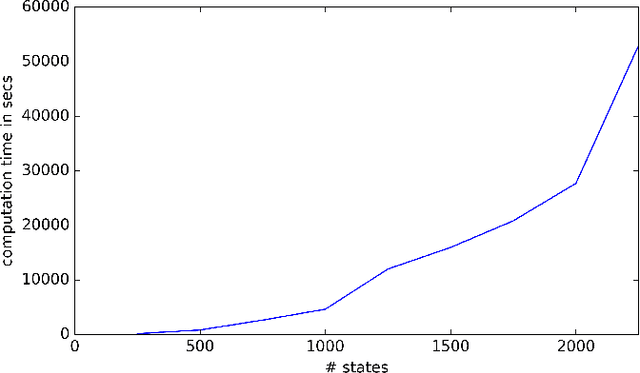
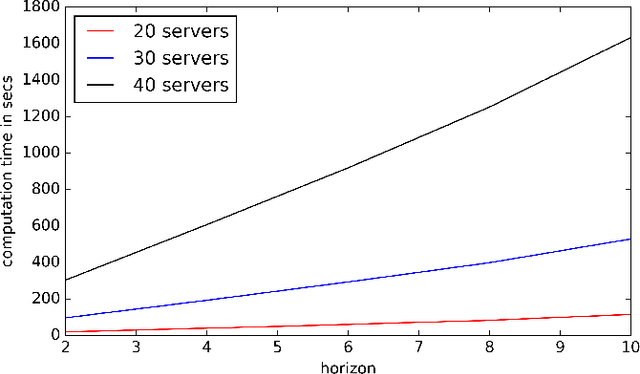
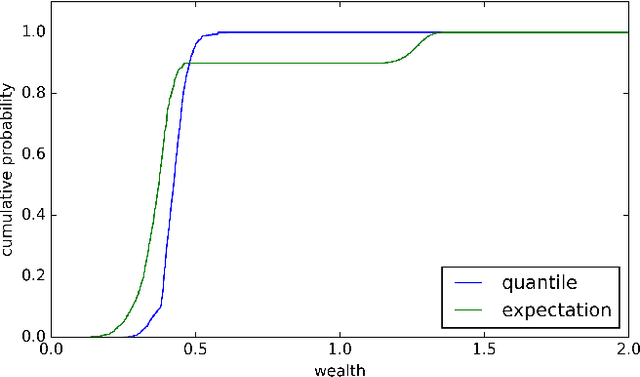
In the Markov decision process model, policies are usually evaluated by expected cumulative rewards. As this decision criterion is not always suitable, we propose in this paper an algorithm for computing a policy optimal for the quantile criterion. Both finite and infinite horizons are considered. Finally we experimentally evaluate our approach on random MDPs and on a data center control problem.
* Long version of AAAI 2017 paper. arXiv admin note: text overlap with
arXiv:1611.00862
View paper on