 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-based Block Coordinate Gradient Coding for Mitigating Partial Stragglers in Distributed Learning
Paper and Code
Jun 06, 2022
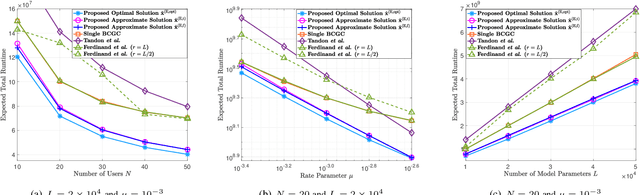


Gradient coding schemes effectively mitigate full stragglers in distributed learning by introducing identical redundancy in coded local partial derivatives corresponding to all model parameters. However, they are no longer effective for partial stragglers as they cannot utilize incomplete computation results from partial stragglers. This paper aims to design a new gradient coding scheme for mitigating partial stragglers in distributed learning. Specifically, we consider a distributed system consisting of one master and N workers, characterized by a general partial straggler model and focuses on solving a general large-scale machine learning problem with L model parameters using gradient coding. First, we propose a coordinate gradient coding scheme with L coding parameters representing L possibly different diversities for the L coordinates, which generates most gradient coding schemes. Then, we consider the minimization of the expected overall runtime and the maximization of the completion probability with respect to the L coding parameters for coordinates, which are challenging discrete optimization problems. To reduce computational complexity, we first transform each to an equivalent but much simpler discrete problem with N\llL variables representing the partition of the L coordinates into N blocks, each with identical redundancy. This indicates an equivalent but more easily implemented block coordinate gradient coding scheme with N coding parameters for blocks. Then, we adopt continuous relaxation to further reduce computational complexity. For the resulting minimization of expected overall runtime, we develop an iterative algorithm of computational complexity O(N^2) to obtain an optimal solution and derive two closed-form approximate solutions both with computational complexity O(N). For the resultant maximization of the completion probability, we develop an iterative algorithm of...