 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPQ: Compressing Deep Neural Networks with One-shot Pruning-Quantization
Paper and Code
May 23, 2022
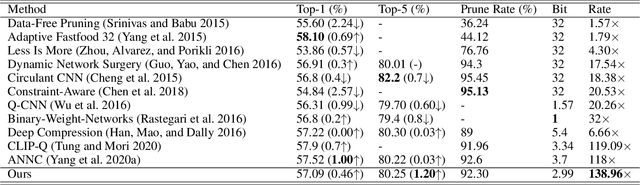
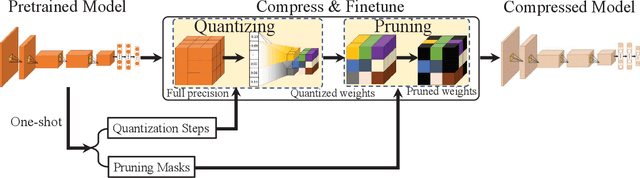

As Deep Neural Networks (DNNs) usually are overparameterized and have millions of weight parameters, it is challenging to deploy these large DNN models on resource-constrained hardware platforms, e.g., smartphones. Numerous network compression methods such as pruning and quantization are proposed to reduce the model size significantly, of which the key is to find suitable compression allocation (e.g., pruning sparsity and quantization codebook) of each layer. Existing solutions obtain the compression allocation in an iterative/manual fashion while finetuning the compressed model, thus suffering from the efficiency issue. Different from the prior art, we propose a novel One-shot Pruning-Quantization (OPQ) in this paper, which analytically solves the compression allocation with pre-trained weight parameters only. During finetuning, the compression module is fixed and only weight parameters are updated. To our knowledge, OPQ is the first work that reveals pre-trained model is sufficient for solving pruning and quantization simultaneously, without any complex iterative/manual optimization at the finetuning stage. Furthermore, we propose a unified channel-wise quantization method that enforces all channels of each layer to share a common codebook, which leads to low bit-rate allocation without introducing extra overhead brought by traditional channel-wise quantization. Comprehensive experiments on ImageNet with AlexNet/MobileNet-V1/ResNet-50 show that our method improves accuracy and training efficiency while obtains significantly higher compression rates compared to the state-of-the-art.