 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Recognition in the Age of Vision-Language Models
Paper and Code
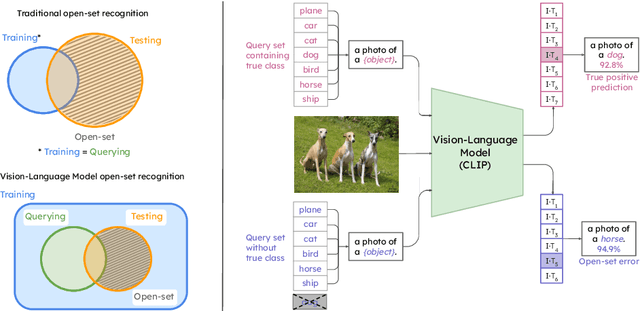
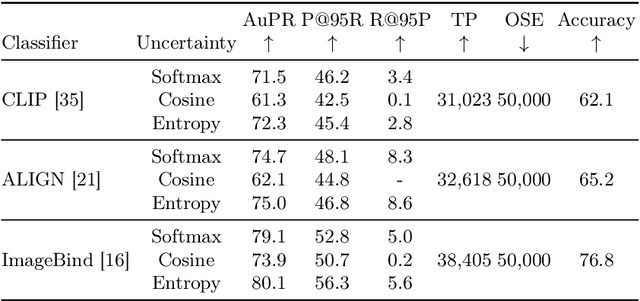
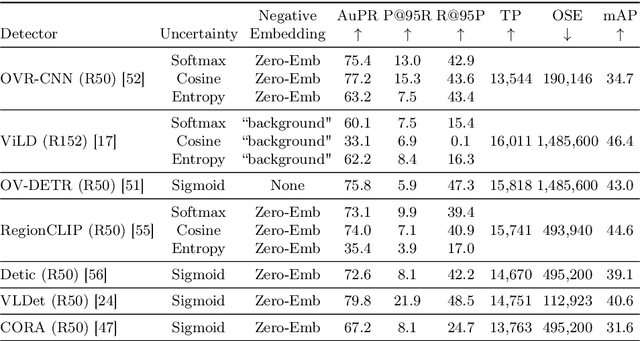
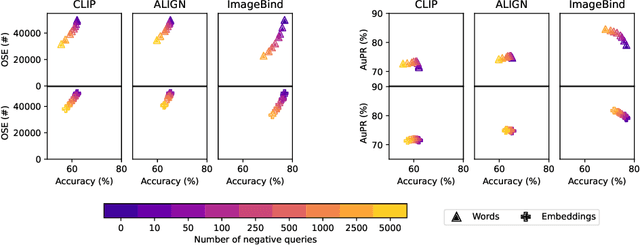
Are vision-language models (VLMs) open-set models because they are trained on internet-scale datasets? We answer this question with a clear no - VLMs introduce closed-set assumptions via their finite query set, making them vulnerable to open-set conditions. We systematically evaluate VLMs for open-set recognition and find they frequently misclassify objects not contained in their query set, leading to alarmingly low precision when tuned for high recall and vice versa. We show that naively increasing the size of the query set to contain more and more classes does not mitigate this problem, but instead causes diminishing task performance and open-set performance. We establish a revised definition of the open-set problem for the age of VLMs, define a new benchmark and evaluation protocol to facilitate standardised evaluation and research in this important area, and evaluate promising baseline approaches based on predictive uncertainty and dedicated negative embeddings on a range of VLM classifiers and object detectors.