 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Stochastic Optimization with Wasserstein Based Non-stationarity
Paper and Code
Dec 23, 2020


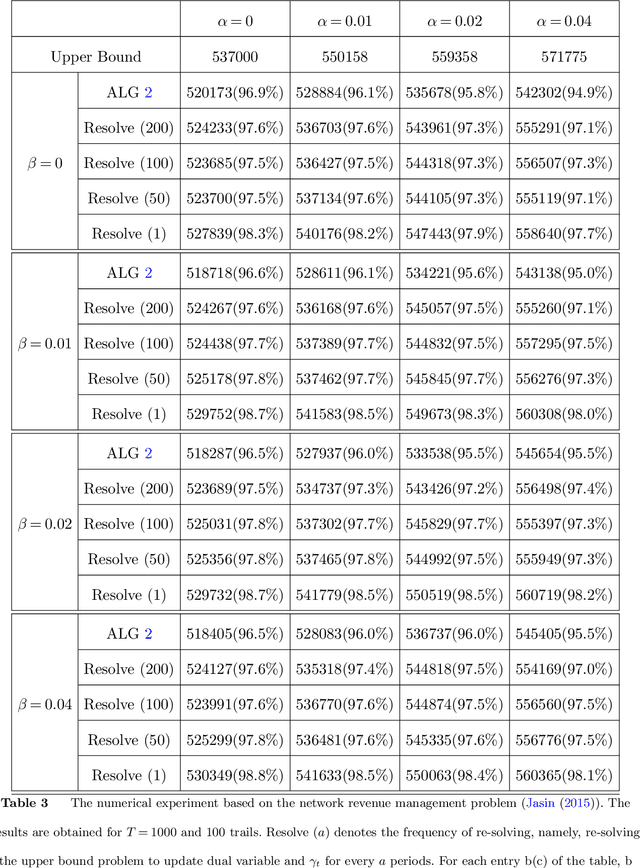
We consider a general online stochastic optimization problem with multiple budget constraints over a horizon of finite time periods. In each time period, a reward function and multiple cost functions are revealed, and the decision maker needs to specify an action from a convex and compact action set to collect the reward and consume the budget. Each cost function corresponds to the consumption of one budget. In each period, the reward and cost functions are drawn from an unknown distribution, which is non-stationary across time. The objective of the decision maker is to maximize the cumulative reward subject to the budget constraints. This formulation captures a wide range of applications including online linear programming and network revenue management, among others. In this paper, we consider two settings: (i) a data-driven setting where the true distribution is unknown but a prior estimate (possibly inaccurate) is available; (ii) an uninformative setting where the true distribution is completely unknown. We propose a unified Wasserstein-distance based measure to quantify the inaccuracy of the prior estimate in setting (i) and the non-stationarity of the system in setting (ii). We show that the proposed measure leads to a necessary and sufficient condition for the attainability of a sublinear regret in both settings. For setting (i), we propose a new algorithm, which takes a primal-dual perspective and integrates the prior information of the underlying distributions into an online gradient descent procedure in the dual space. The algorithm also naturally extends to the uninformative setting (ii). Under both settings, we show the corresponding algorithm achieves a regret of optimal order. In numerical experiments, we demonstrate how the proposed algorithms can be naturally integrated with the re-solving technique to further boost the empirical performance.