 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Meta-Learning on Non-convex Setting
Paper and Code
Oct 22, 2019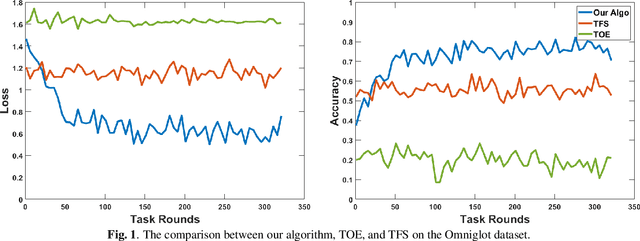
The online meta-learning framework is designed for the continual lifelong learning setting. It bridges two fields: meta-learning which tries to extract prior knowledge from existing tasks for fast learning of future tasks, and online-learning which focuses on the sequential setting in which problems are revealed one by one. In this paper, we generalize the original framework from convex to non-convex setting, and introduce the local regret as the alternative performance measure. We then apply this framework to stochastic settings, and show theoretically that it enjoys a logarithmic local regret, and is robust to any hyperparameter initialization. The empirical test on a real-world task demonstrates its superiority compared with traditional methods.