 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning With Adaptive Rebalancing in Nonstationary Environments
Paper and Code

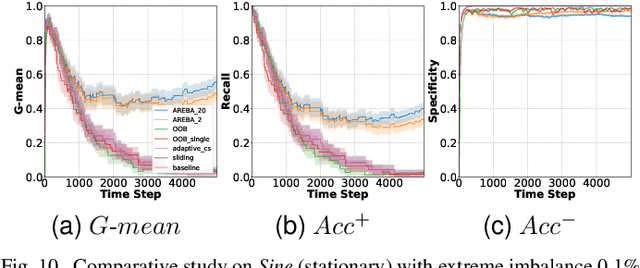

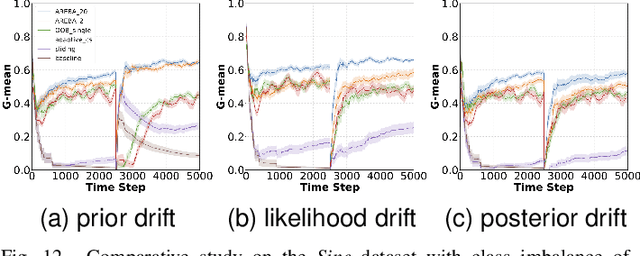
An enormous and ever-growing volume of data is nowadays becoming available in a sequential fashion in various real-world applications. Learning in nonstationary environments constitutes a major challenge, and this problem becomes orders of magnitude more complex in the presence of class imbalance. We provide new insights into learning from nonstationary and imbalanced data in online learning, a largely unexplored area. We propose the novel Adaptive REBAlancing (AREBA) algorithm that selectively includes in the training set a subset of the majority and minority examples that appeared so far, while at its heart lies an adaptive mechanism to continually maintain the class balance between the selected examples. We compare AREBA with strong baselines and other state-of-the-art algorithms and perform extensive experimental work in scenarios with various class imbalance rates and different concept drift types on both synthetic and real-world data. AREBA significantly outperforms the rest with respect to both learning speed and learning quality. Our code is made publicly available to the scientific community.