 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline continual learning with no task boundaries
Paper and Code
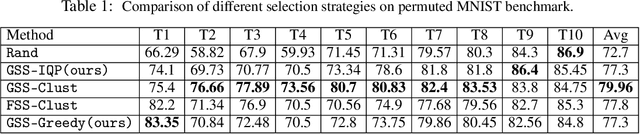

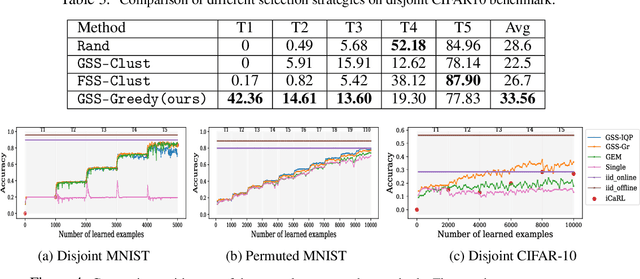
Continual learning is the ability of an agent to learn online with a non-stationary and never-ending stream of data. A key component for such never-ending learning process is to overcome the catastrophic forgetting of previously seen data, a problem that neural networks are well known to suffer from. The solutions developed so far often relax the problem of continual learning to the easier task-incremental setting, where the stream of data is divided into tasks with clear boundaries. In this paper, we break the limits and move to the more challenging online setting where we assume no information of tasks in the data stream. We start from the idea that each learning step should not increase the losses of the previously learned examples through constraining the optimization process. This means that the number of constraints grows linearly with the number of examples, which is a serious limitation. We develop a solution to select a fixed number of constraints that we use to approximate the feasible region defined by the original constraints. We compare our approach against the methods that rely on task boundaries to select a fixed set of examples, and show comparable or even better results, especially when the boundaries are blurry or when the data distributions are imbalanced.