 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Budgeted Learning for Classifier Induction
Paper and Code
Mar 13, 2019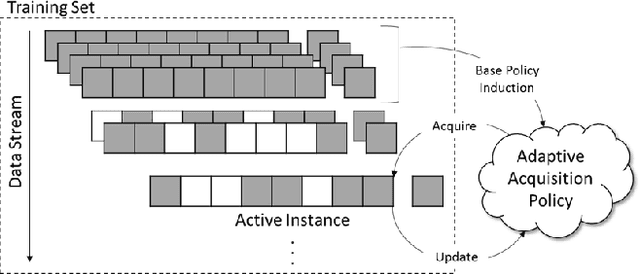
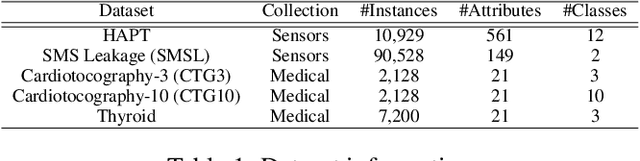
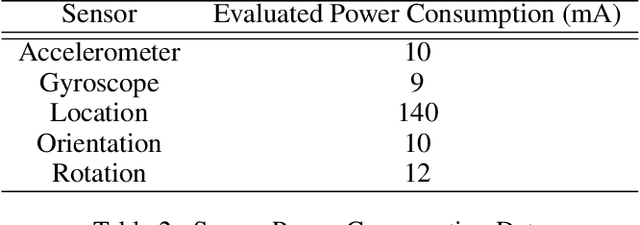
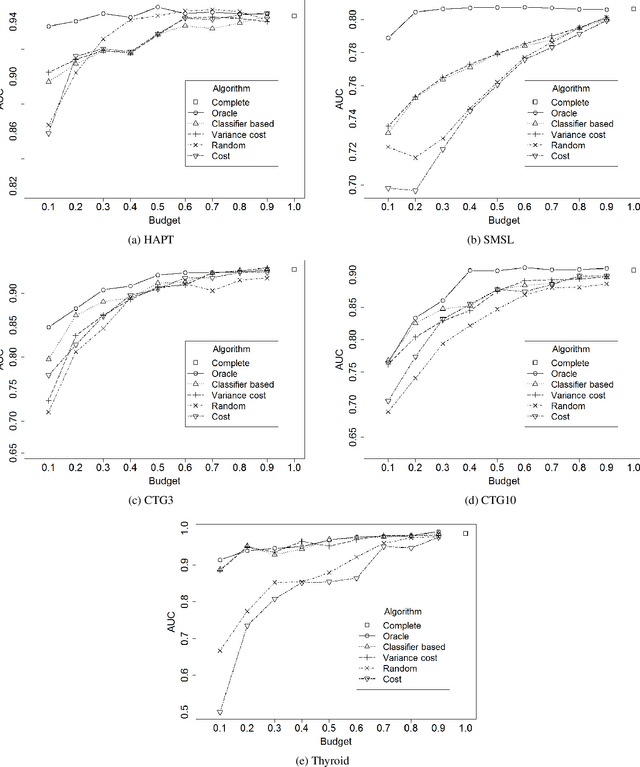
In real-world machine learning applications, there is a cost associated with sampling of different features. Budgeted learning can be used to select which feature-values to acquire from each instance in a dataset, such that the best model is induced under a given constraint. However, this approach is not possible in the domain of online learning since one may not retroactively acquire feature-values from past instances. In online learning, the challenge is to find the optimum set of features to be acquired from each instance upon arrival from a data stream. In this paper we introduce the issue of online budgeted learning and describe a general framework for addressing this challenge. We propose two types of feature value acquisition policies based on the multi-armed bandit problem: random and adaptive. Adaptive policies perform online adjustments according to new information coming from a data stream, while random policies are not sensitive to the information that arrives from the data stream. Our comparative study on five real-world datasets indicates that adaptive policies outperform random policies for most budget limitations and datasets. Furthermore, we found that in some cases adaptive policies achieve near-optimal results.