 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-To-Many Multilingual End-to-end Speech Translation
Paper and Code

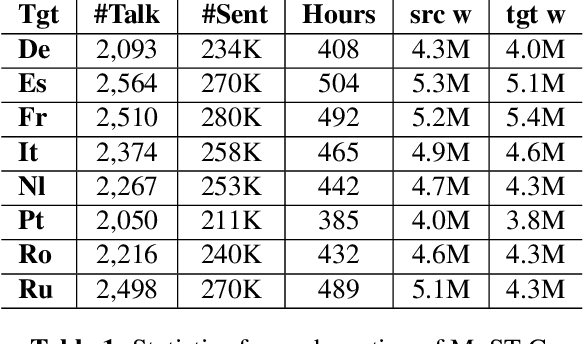
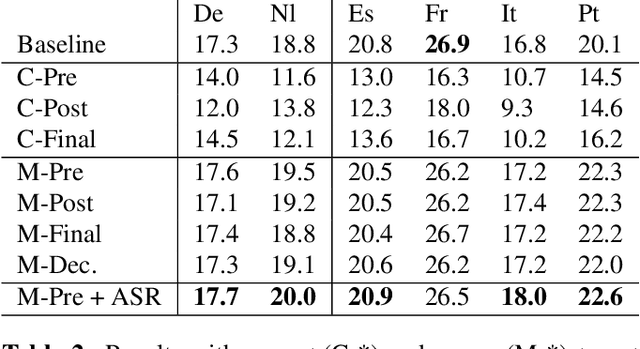

Nowadays, training end-to-end neural models for spoken language translation (SLT) still has to confront with extreme data scarcity conditions. The existing SLT parallel corpora are indeed orders of magnitude smaller than those available for the closely related tasks of automatic speech recognition (ASR) and machine translation (MT), which usually comprise tens of millions of instances. To cope with data paucity, in this paper we explore the effectiveness of transfer learning in end-to-end SLT by presenting a multilingual approach to the task. Multilingual solutions are widely studied in MT and usually rely on ``\textit{target forcing}'', in which multilingual parallel data are combined to train a single model by prepending to the input sequences a language token that specifies the target language. However, when tested in speech translation, our experiments show that MT-like \textit{target forcing}, used as is, is not effective in discriminating among the target languages. Thus, we propose a variant that uses target-language embeddings to shift the input representations in different portions of the space according to the language, so to better support the production of output in the desired target language. Our experiments on end-to-end SLT from English into six languages show important improvements when translating into similar languages, especially when these are supported by scarce data. Further improvements are obtained when using English ASR data as an additional language (up to $+2.5$ BLEU points).