 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Network, Many Masks: Towards More Parameter-Efficient Transfer Learning
Paper and Code

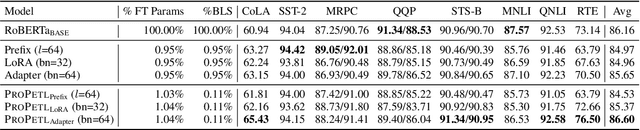

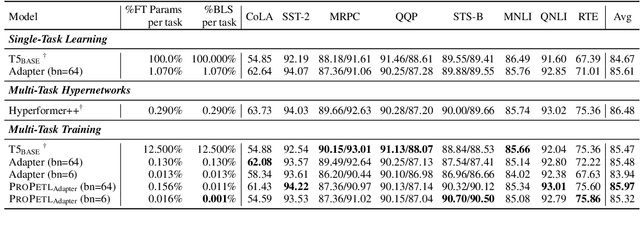
Fine-tuning pre-trained language models for multiple tasks tends to be expensive in terms of storage. To mitigate this, parameter-efficient transfer learning (PETL) methods have been proposed to address this issue, but they still require a significant number of parameters and storage when being applied to broader ranges of tasks. To achieve even greater storage reduction, we propose PROPETL, a novel method that enables efficient sharing of a single PETL module which we call prototype network (e.g., adapter, LoRA, and prefix-tuning) across layers and tasks. We then learn binary masks to select different sub-networks from the shared prototype network and apply them as PETL modules into different layers. We find that the binary masks can determine crucial information from the network, which is often ignored in previous studies. Our work can also be seen as a type of pruning method, where we find that overparameterization also exists in the seemingly small PETL modules. We evaluate PROPETL on various downstream tasks and show that it can outperform other PETL methods with approximately 10% of the parameter storage required by the latter.