 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Subbagging Estimation for Massive Data
Paper and Code
Feb 28, 2021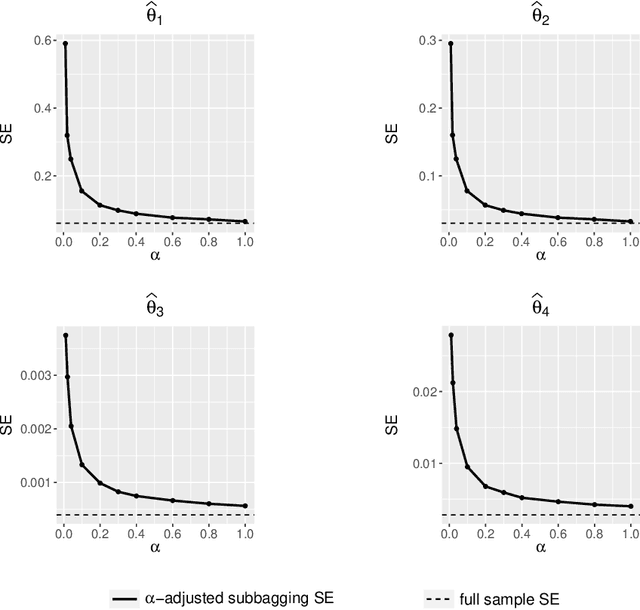
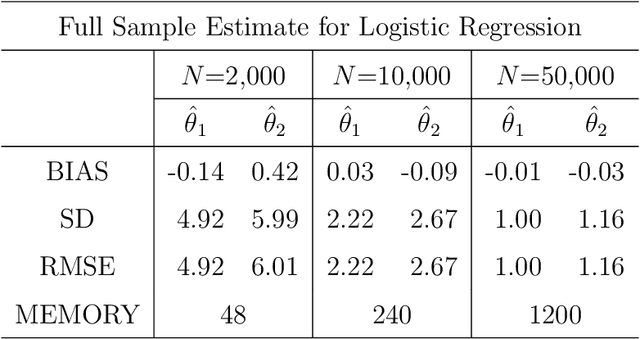
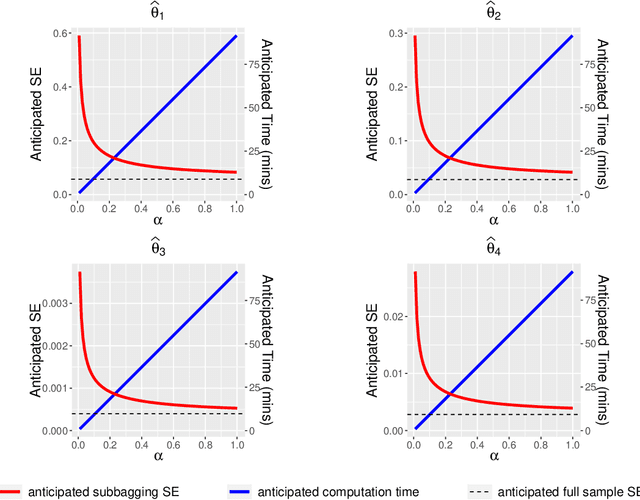
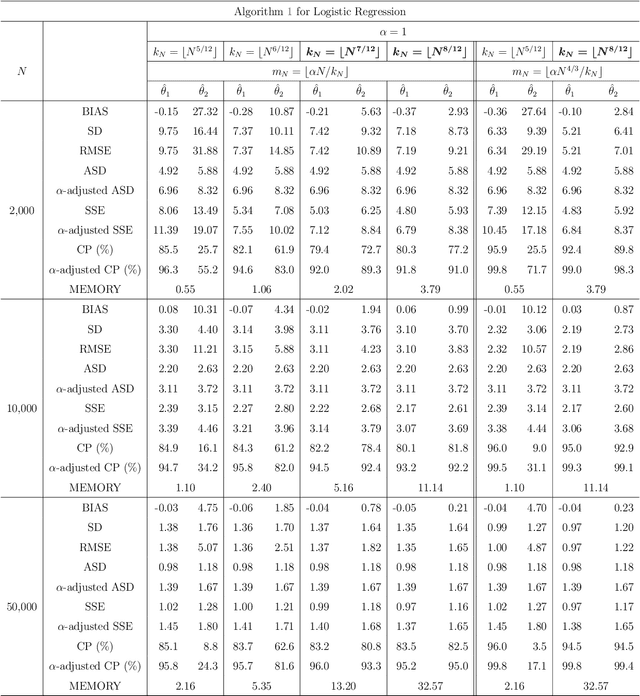
This article introduces subbagging (subsample aggregating) estimation approaches for big data analysis with memory constraints of computers. Specifically, for the whole dataset with size $N$, $m_N$ subsamples are randomly drawn, and each subsample with a subsample size $k_N\ll N$ to meet the memory constraint is sampled uniformly without replacement. Aggregating the estimators of $m_N$ subsamples can lead to subbagging estimation. To analyze the theoretical properties of the subbagging estimator, we adapt the incomplete $U$-statistics theory with an infinite order kernel to allow overlapping drawn subsamples in the sampling procedure. Utilizing this novel theoretical framework, we demonstrate that via a proper hyperparameter selection of $k_N$ and $m_N$, the subbagging estimator can achieve $\sqrt{N}$-consistency and asymptotic normality under the condition $(k_Nm_N)/N\to \alpha \in (0,\infty]$. Compared to the full sample estimator, we theoretically show that the $\sqrt{N}$-consistent subbagging estimator has an inflation rate of $1/\alpha$ in its asymptotic variance. Simulation experiments are presented to demonstrate the finite sample performances. An American airline dataset is analyzed to illustrate that the subbagging estimate is numerically close to the full sample estimate, and can be computationally fast under the memory constraint.