 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the properties of variational approximations of Gibbs posteriors
Paper and Code
Jun 15, 2015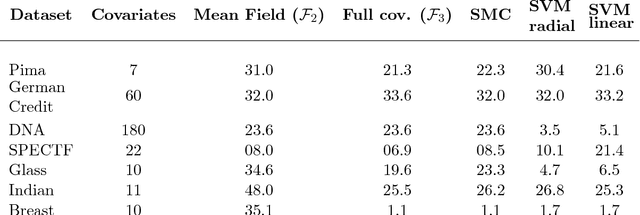
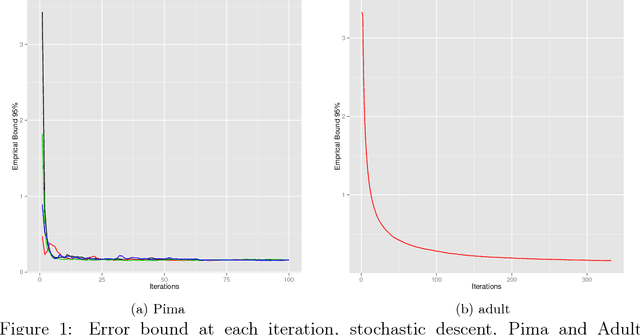
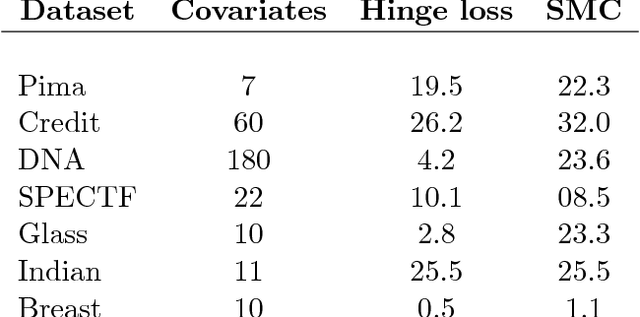
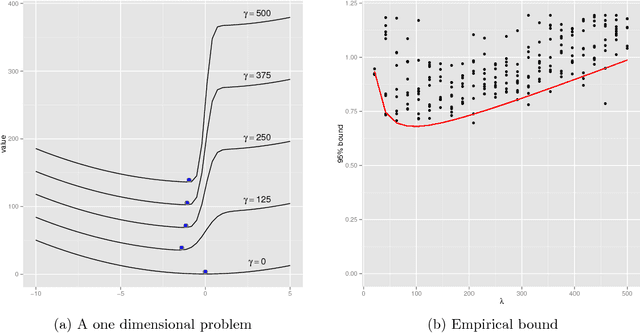
The PAC-Bayesian approach is a powerful set of techniques to derive non- asymptotic risk bounds for random estimators. The corresponding optimal distribution of estimators, usually called the Gibbs posterior, is unfortunately intractable. One may sample from it using Markov chain Monte Carlo, but this is often too slow for big datasets. We consider instead variational approximations of the Gibbs posterior, which are fast to compute. We undertake a general study of the properties of such approximations. Our main finding is that such a variational approximation has often the same rate of convergence as the original PAC-Bayesian procedure it approximates. We specialise our results to several learning tasks (classification, ranking, matrix completion),discuss how to implement a variational approximation in each case, and illustrate the good properties of said approximation on real datasets.