 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Learning Dynamics of Deep Neural Networks
Paper and Code
Sep 18, 2018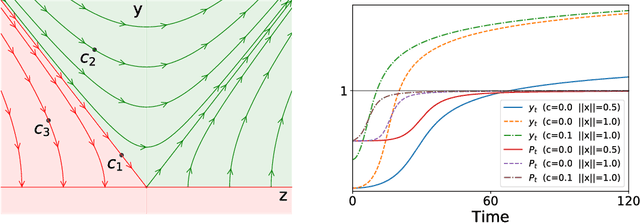
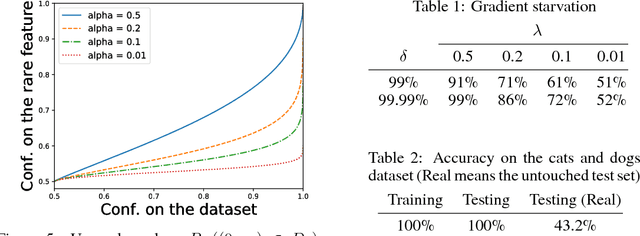
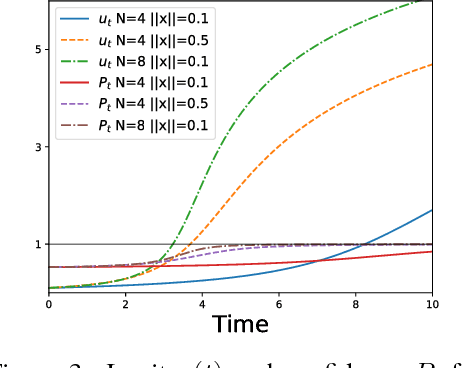
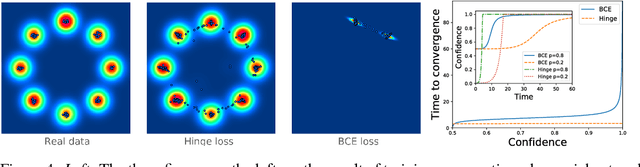
While a lot of progress has been made in recent years, the dynamics of learning in deep nonlinear neural networks remain to this day largely misunderstood. In this work, we study the case of binary classification and prove various properties of learning in such networks under strong assumptions such as linear separability of the data. Extending existing results from the linear case, we confirm empirical observations by proving that the classification error also follows a sigmoidal shape in nonlinear architectures. We show that given proper initialization, learning expounds parallel independent modes and that certain regions of parameter space might lead to failed training. We also demonstrate that input norm and features' frequency in the dataset lead to distinct convergence speeds which might shed some light on the generalization capabilities of deep neural networks. We provide a comparison between the dynamics of learning with cross-entropy and hinge losses, which could prove useful to understand recent progress in the training of generative adversarial networks. Finally, we identify a phenomenon that we baptize gradient starvation where the most frequent features in a dataset prevent the learning of other less frequent but equally informative features.