 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Random Seeds on the Fairness of Clinical Classifiers
Paper and Code
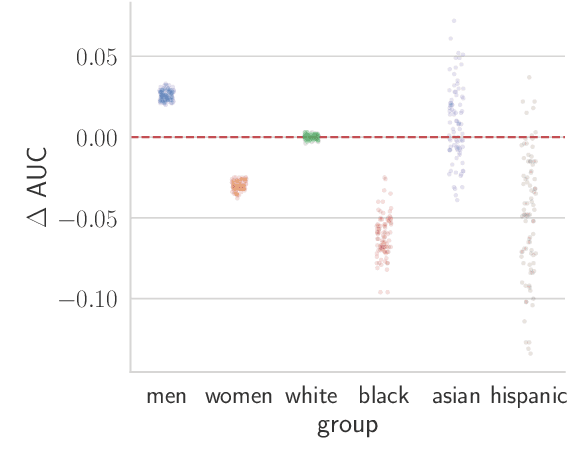
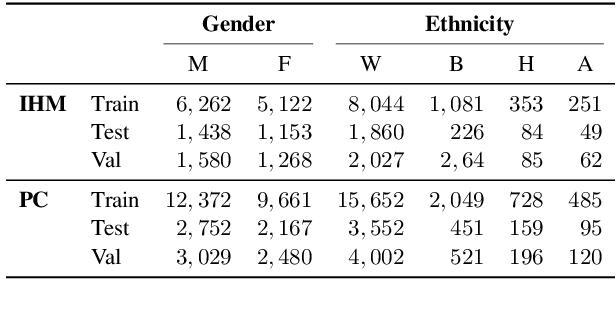
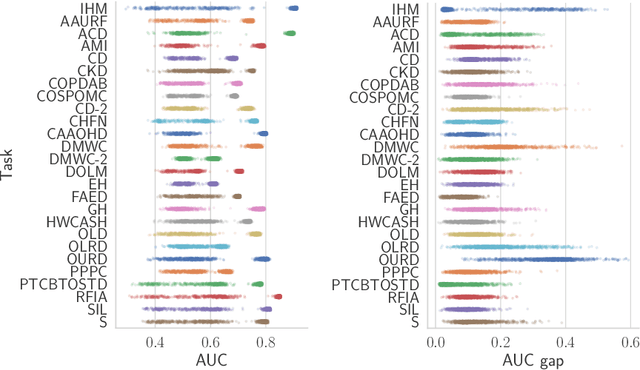
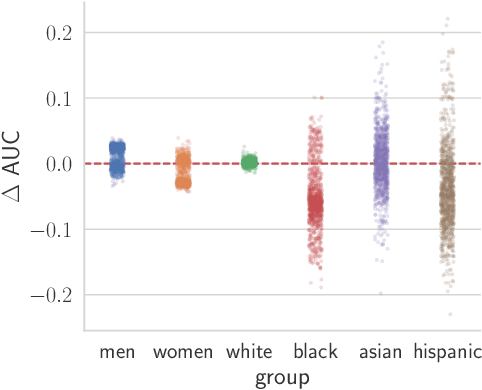
Recent work has shown that fine-tuning large networks is surprisingly sensitive to changes in random seed(s). We explore the implications of this phenomenon for model fairness across demographic groups in clinical prediction tasks over electronic health records (EHR) in MIMIC-III -- the standard dataset in clinical NLP research. Apparent subgroup performance varies substantially for seeds that yield similar overall performance, although there is no evidence of a trade-off between overall and subgroup performance. However, we also find that the small sample sizes inherent to looking at intersections of minority groups and somewhat rare conditions limit our ability to accurately estimate disparities. Further, we find that jointly optimizing for high overall performance and low disparities does not yield statistically significant improvements. Our results suggest that fairness work using MIMIC-III should carefully account for variations in apparent differences that may arise from stochasticity and small sample sizes.