 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the expressiveness and spectral bias of KANs
Paper and Code
Oct 02, 2024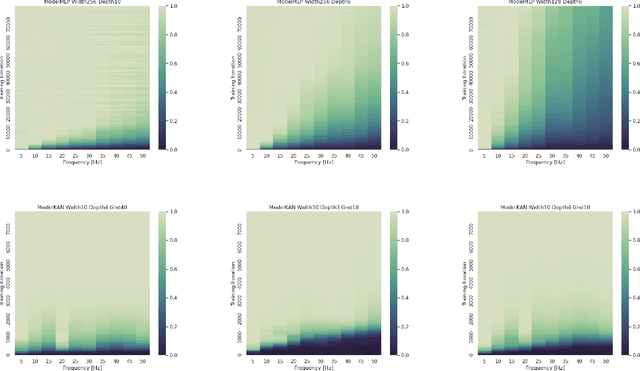


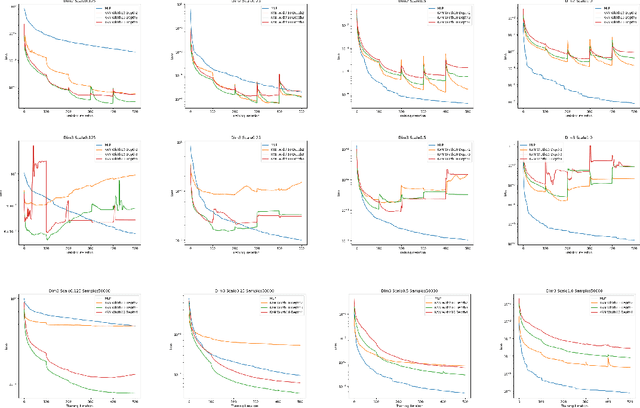
Kolmogorov-Arnold Networks (KAN) \cite{liu2024kan} were very recently proposed as a potential alternative to the prevalent architectural backbone of many deep learning models, the multi-layer perceptron (MLP). KANs have seen success in various tasks of AI for science, with their empirical efficiency and accuracy demostrated in function regression, PDE solving, and many more scientific problems. In this article, we revisit the comparison of KANs and MLPs, with emphasis on a theoretical perspective. On the one hand, we compare the representation and approximation capabilities of KANs and MLPs. We establish that MLPs can be represented using KANs of a comparable size. This shows that the approximation and representation capabilities of KANs are at least as good as MLPs. Conversely, we show that KANs can be represented using MLPs, but that in this representation the number of parameters increases by a factor of the KAN grid size. This suggests that KANs with a large grid size may be more efficient than MLPs at approximating certain functions. On the other hand, from the perspective of learning and optimization, we study the spectral bias of KANs compared with MLPs. We demonstrate that KANs are less biased toward low frequencies than MLPs. We highlight that the multi-level learning feature specific to KANs, i.e. grid extension of splines, improves the learning process for high-frequency components. Detailed comparisons with different choices of depth, width, and grid sizes of KANs are made, shedding some light on how to choose the hyperparameters in practice.